Hello, I wanted to share this evening a scan I just finished. It is linked to in this thread where I will continue adding ESS-related materials (for those interested in that sort of thing):
http://www.classicrotaryphones.com/forum/index.php?topic=28001.0
The document therein is the Guide to Stored Program Control Switching, a Bell System document concerning #1 and #2 ESS telephone exchanges and varieties of networking connections. It's interesting in that the guide is three separate little flip decks of cards, some of which can represent steps in a network. Flip to the components you need and the traces at the edges meet to create a diagram of that particular configuration. I quite like the concept, seems like a great way to visualize variable networks.
Anywho, as mentioned I'm going to be putting some more ESS stuff up there, mostly related to 5ESS and 3B20 computers. That seems to now squarely be my main documentation focus since I'm starting to bleed the Bell System UNIX well a bit dry of stuff I can randomly find on eBay. 5ESS and 3B20 are still adjacent enough that I'm sure UNIX-y things will be scattered throughout this material.
Finally, a long shot but is anyone aware of preserved copies (or in possession of) the March 1980 issue of the Bell Laboratories Record? An index on archive.org indicates that issue has a focus piece on the 3B20 which I am quite interested in getting eyes on. I've come across several other copies around this time frame, some of which I've purchased to scan, but not this one yet.
As always happy to answer any questions about what I'm working on or consider scanning jobs for other documentation folks have leads on, happy new year everyone!
- Matt G.
[TUHS as Bcc]
I just saw sad news from Bertrand Meyer. Apparently, Niklaus Wirth
passed away on the 1st. :-(
I think it's fair to say that it is nearly impossible to overstate his
influence on modern programming.
- Dan C.
Dyslexia sucks... sorry, if it was not obvious, please globally substitute
s:STOP/STOP:START/STOP:
ᐧ
On Sun, Dec 31, 2023 at 2:30 PM Clement T Cole via groups.io <clemc=
ccc.com(a)groups.io> wrote:
> Small PS below...
>
> On Sat, Dec 30, 2023 at 9:27 PM Clement T Cole via groups.io <clemc=
> ccc.com(a)groups.io> wrote:
>
>>
>> I did not say that or imply it. But variable vs. fixed blocking has
>> implications on both mechanical requirements and ends up being reflected in
>> how the sw handles it. Traditional 9-track allows you to mix record sizes
>> on each tape. Streamer formats don’t traditionally allow that because they
>> restrict / remove inter record gaps in the same manner 9-track supports.
>> This increases capacity of the tape (less waste).
>>
>
> In my explanation, I may have been a tad confusing. When I say fixed
> records -- I mean on-tape fixed records, what the QIC-24/120/150 standard
> refers to as: "*A group of consecutive bits comprising of a preamble,
> data block marker, a single data block, block address and CRC and postamble*"
> [the standard previous defines a data black os 512 consecutive bytes] --*
> i.e*., if you put an o'scope on the tape head and looked at the bit
> stream (see page 16 of QIC-120 Rev F - Section 5 "Recorded Block" for a
> picture of this format -- note is can only address 2^20 blocks per track,
> but it supports addressing to 256 tracks -- with 15 tracks of QIC-120 that
> means 15728640 unique 512-byte blocks).
>
> STOP/STOP does something similar but encodes the LRECL used [I don't have
> the ANSI tape standard handy - but I remember seeing a wonderful picture of
> all this from said documents when I first was educated about tapes in my
> old IBM days ~50 years ago]. After each record, STOP/STOP needs an
> "Inter-Record-Gap" (IRC) to allow for the motor's spin-up/spin-down time
> before continuing the bit stream of the next data block. The IRC distance
> is something like 5-10 mm [which is a great deal compared to the size of a
> bit when using GCR encoding (which is what 6250 BPI and QIC both use).
> These gaps take space (capacity) from the tape, so people tend to write
> with larger blocking factors [UNIX traditionally uses 10240 bytes- other
> systems use other values - as I said, I believe the standard says the max
> is 64K bytes).
>
> Since streamers (like QIC tape) are supposed to be continuous, the QIC
> inter-records gaps resemble fixed disk records and can be extremely small.
> Remember, each bit is measured in micrometers -- about *2 micrometers*,
> IIRC for QIC and around 10 for ½" formats -- again, and I would need to
> check the ANSI spec, which is not handy. But this is a huge space savings
> even with a smallish block (512) -- again - this was lifted from disk
> technology of the day which had often standardized on 512 8-bit byte blocks
> by then.
>
> BTW: this is again why I suspect a TK25 tape is not going to be able to
> read on QIC-24/120/150 drive if, indeed, page 1-5 of the TK25 user manual
> says it supports four different block sizes [1K/2K/4K/8K]. First, the
> data block format would have to be variable to 4 sizes, and second, the
> preamble would need to encode and write what size block to expect on
> read. Unfortunately, that document does not say much more about the
> physical tape format other than it can use cartridges "similar to ANSI
> Standard X3.55-1982" (which is a 3M DC-600A tape cartridge), has "11
> tracks, 8000 bpi" recording density (/w 10000 flux reversals per in), using
> a "single track NRZI dat in a serpentine pattern, with 4-5 run length
> limited code similar to GCR."
>
> That said, most modern SW will allow you to *write* different size record
> sizes (LRECL) in the user software, but the QIC drives and I believe things
> like DAT and Exabyte will only write 512-byte blocks, so somewhere between
> your user program and tape itself, the write will be broken into N 512 byte
> blocks and then pad (with null is typical) the last block to 512 bytes.
> My memory is the QIC standard is silent on where that is done, but I
> suspect it's done in the controller and the driver is forced to send it
> 512-byte blocks.
>
> So, while you may define blocks of different sizes, unlike ½", it will
> always be written as 512-byte blocks.
>
> That said, using larger record sizes in your application SW can have huge
> performance wins (which I mentioned in my first message) - *e.g.*,
> keeping the drive streaming as more user data has been locked down in
> memory for a DMA. But by the time the driver and the controller are
> finished, it's fixed 512-byte blocks on the tape.
>
>
> One other thing is WRT to QIC, which differs from other schemes. I
> previously mentioned tape files - a feature of the ½" physical tape formats
> not typically supported for QIC tapes. QIC has an interesting feature that
> allows a block to be rewritten and replaced later on the tape (see the
> section of spec/you user manual WRT for "rewritten" or "replacement
> "blocks). I've forgotten all the details, but I seem to remember that
> features were why multiple tape files were difficult to implement.
> Someone who knows more about tapes may remember the details/be able to
> explain -- I remember dealing with tape files was a PITA in QIC, and the
> logic in a standard ½" tape driver could not be just cloned for the QIC
> driver.
> ᐧ
> ᐧ
> ᐧ
> _._,_._,_
> ------------------------------
> Groups.io Links:
>
> You receive all messages sent to this group.
>
> View/Reply Online (#3631) <https://groups.io/g/simh/message/3631> | Reply
> To Group
> <simh@groups.io?subject=Re:%20Re%3A%20%5Bsimh%5D%20Old%20VAX%2FVMS%20Tapes>
> | Reply To Sender
> <clemc@ccc.com?subject=Private:%20Re:%20Re%3A%20%5Bsimh%5D%20Old%20VAX%2FVMS%20Tapes>
> | Mute This Topic <https://groups.io/mt/103433309/4811590> | New Topic
> <https://groups.io/g/simh/post>
> Your Subscription <https://groups.io/g/simh/editsub/4811590> | Contact
> Group Owner <simh+owner(a)groups.io> | Unsubscribe
> <https://groups.io/g/simh/leave/8620764/4811590/1680534689/xyzzy> [
> clemc(a)ccc.com]
> _._,_._,_
>
>
Small PS below...
On Sat, Dec 30, 2023 at 9:27 PM Clement T Cole via groups.io <clemc=
ccc.com(a)groups.io> wrote:
>
> I did not say that or imply it. But variable vs. fixed blocking has
> implications on both mechanical requirements and ends up being reflected in
> how the sw handles it. Traditional 9-track allows you to mix record sizes
> on each tape. Streamer formats don’t traditionally allow that because they
> restrict / remove inter record gaps in the same manner 9-track supports.
> This increases capacity of the tape (less waste).
>
In my explanation, I may have been a tad confusing. When I say fixed
records -- I mean on-tape fixed records, what the QIC-24/120/150 standard
refers to as: "*A group of consecutive bits comprising of a preamble, data
block marker, a single data block, block address and CRC and postamble*"
[the standard previous defines a data black os 512 consecutive bytes] --*
i.e*., if you put an o'scope on the tape head and looked at the bit
stream (see page 16 of QIC-120 Rev F - Section 5 "Recorded Block" for a
picture of this format -- note is can only address 2^20 blocks per track,
but it supports addressing to 256 tracks -- with 15 tracks of QIC-120 that
means 15728640 unique 512-byte blocks).
STOP/STOP does something similar but encodes the LRECL used [I don't have
the ANSI tape standard handy - but I remember seeing a wonderful picture of
all this from said documents when I first was educated about tapes in my
old IBM days ~50 years ago]. After each record, STOP/STOP needs an
"Inter-Record-Gap" (IRC) to allow for the motor's spin-up/spin-down time
before continuing the bit stream of the next data block. The IRC distance
is something like 5-10 mm [which is a great deal compared to the size of a
bit when using GCR encoding (which is what 6250 BPI and QIC both use).
These gaps take space (capacity) from the tape, so people tend to write
with larger blocking factors [UNIX traditionally uses 10240 bytes- other
systems use other values - as I said, I believe the standard says the max
is 64K bytes).
Since streamers (like QIC tape) are supposed to be continuous, the QIC
inter-records gaps resemble fixed disk records and can be extremely small.
Remember, each bit is measured in micrometers -- about *2 micrometers*,
IIRC for QIC and around 10 for ½" formats -- again, and I would need to
check the ANSI spec, which is not handy. But this is a huge space savings
even with a smallish block (512) -- again - this was lifted from disk
technology of the day which had often standardized on 512 8-bit byte blocks
by then.
BTW: this is again why I suspect a TK25 tape is not going to be able to
read on QIC-24/120/150 drive if, indeed, page 1-5 of the TK25 user manual
says it supports four different block sizes [1K/2K/4K/8K]. First, the
data block format would have to be variable to 4 sizes, and second, the
preamble would need to encode and write what size block to expect on
read. Unfortunately, that document does not say much more about the
physical tape format other than it can use cartridges "similar to ANSI
Standard X3.55-1982" (which is a 3M DC-600A tape cartridge), has "11
tracks, 8000 bpi" recording density (/w 10000 flux reversals per in), using
a "single track NRZI dat in a serpentine pattern, with 4-5 run length
limited code similar to GCR."
That said, most modern SW will allow you to *write* different size record
sizes (LRECL) in the user software, but the QIC drives and I believe things
like DAT and Exabyte will only write 512-byte blocks, so somewhere between
your user program and tape itself, the write will be broken into N 512 byte
blocks and then pad (with null is typical) the last block to 512 bytes.
My memory is the QIC standard is silent on where that is done, but I
suspect it's done in the controller and the driver is forced to send it
512-byte blocks.
So, while you may define blocks of different sizes, unlike ½", it will
always be written as 512-byte blocks.
That said, using larger record sizes in your application SW can have huge
performance wins (which I mentioned in my first message) - *e.g.*, keeping
the drive streaming as more user data has been locked down in memory for a
DMA. But by the time the driver and the controller are finished, it's fixed
512-byte blocks on the tape.
One other thing is WRT to QIC, which differs from other schemes. I
previously mentioned tape files - a feature of the ½" physical tape formats
not typically supported for QIC tapes. QIC has an interesting feature that
allows a block to be rewritten and replaced later on the tape (see the
section of spec/you user manual WRT for "rewritten" or "replacement
"blocks). I've forgotten all the details, but I seem to remember that
features were why multiple tape files were difficult to implement.
Someone who knows more about tapes may remember the details/be able to
explain -- I remember dealing with tape files was a PITA in QIC, and the
logic in a standard ½" tape driver could not be just cloned for the QIC
driver.
ᐧ
ᐧ
ᐧ
> From: Derek Fawcus
> How early does that have to be? MP/M-1.0 (1979 spec) mentions this, as
> "Resident System Processes" ... It was a banked switching, multiuser,
> multitasking system for a Z80/8080.
Anything with a microprocessor is, by definition, late! :-)
I'm impressed, in retrospect, with how quickly the world went from proceesors
built with transistors, through proceesors built out discrete ICs, to
microprocessors. To give an example; the first DEC machine with an IC
processor was the -11/20, in 1970 (the KI10 was 1972); starting with the
LSI-11, in 1975, DEC started using microprocessors; the last PDP-11 with a
CPU made out of of discrete ICs was the -11/44, in 1979. All -11's produced
after that used microprocessors.
So just 10 years... Wow.
Noel
We should move to COFF (cc’ed) for any further discussion. This is way off
topic for simh.
Below
Sent from a handheld expect more typos than usual
On Sat, Dec 30, 2023 at 7:59 PM Nigel Johnson MIEEE via groups.io
<nw.johnson=ieee.org(a)groups.io> wrote:
> First of all, 7-track vs 9-yrack - when you are streaming in serpentine
> mode, it is whatever you can fit into the tape width having regard to the
> limitations of the stepper motor accuracy.
>
Agreed. It’s the physical size of head and encoding magnetics. Parallel
you have n heads together all reading or writing together into n analog
circuits. A rake across the ground if you will. Serial of course its
like a single pencil line with the head on a servo starting in the center
of the tape and when you hit the physical eot move it up or down as
appropriate.
It is nothing to do with the number of bits per data unit.
>
I did not say that or imply it. But variable vs. fixed blocking has
implications on both mechanical requirements and ends up being reflected in
how the sw handles it. Traditional 9-track allows you to mix record sizes
on each tape. Streamer formats don’t traditionally allow that because they
restrict / remove inter record gaps in the same manner 9-track supports.
This increases capacity of the tape (less waste).
Just for comparison at 6250 BPI a traditional 2400’ ½” tape writing fixed
blocks of 10240 8-bit bytes gets about 150Mbytes. A ¼” DC-6150 tape using
QIC-150 only one forth the length and half as wide gets the same capacity
and they both use the same core scheme to encode the bits. QIC writes
smaller bits and wastes less tape with IRCs.
That all said, Looking at the TK25 specs besides being 11 tracks it is also
supports a small number different block sizes (LRECL) - unlike QIC.
Nothing like 9-track which can handle a large range of LRECLs. What I
don’t see in the TK25 is if you can mix them on a tape or if that is coded
once for each tape as opposed in each record.
Btw while I don’t think ansi condones it, some 9-track units like the
Storage Tek ones could not only write different LRECLs but could write
using different encoding (densities) on the same medium. This sad trick
confused many drives when you moved the tape to a drive that could not. I
have some interesting customer stories living those issues. But I digress …
FWIW As I said before do have a lot of experience with what it takes to
support this stuff and what you have to do decode it, the drivers for same
et al. I never considered myself a tape expert- there are many the know
way more than I - but I have lived, experienced and had to support a number
of these systems and have learned the hard way about how these schemes can
go south when trying to recover data.
Back in the beginning of my career, we had Uniservo VIC drives which were
> actually 7-bit parallel! (256, 556, and 800 bpi! NRZI
>
Yep same here. ½” was 5, 7 and 9 bits in parallel originally. GE-635 has
in the late 1960s then and a IBM shop in the early 70s. And of course saw
my favorite tapes of all - original DEC tape. I’ve also watched things
change with serial and the use of serpentine encoding.
You might find it amusing — any early 1980s Masscomp machines had a special
½” drive that had a huge number serpentine tracks I’ve forgotten the exact
amount. They used traditional 1/2” spools from 3M and the like but r/w was
custom to the drive. I’ve forgotten the capacity but at the time it was
huge. What I remember it was much higher capacity and reliability than
exabyte which at the time was the capacity leader. The USAF AWACS planes
had 2 plus a spare talking to the /700 systems doing the I/O - they were
suckling up everything in the air and recording it as digital signals. The
tape units were Used to record all that data. An airman spends his/whole
time loading and unloading tapes. Very cool system.
> Some things about the 92192 drive: it was 8" cabinet format in a 5.25
> inch world so needed an external box. It also had an annoying habit, given
> Control Data's proclivity for perfection, that when you put a cartridge in,
> it ran it back and forth for five minutes before coming ready to ensure
> even tension on the tape!
>
> The formatter-host adapter bus was not QIC36, so Emulex had to make a
> special controller, the TC05, to handle the CDC Proprietary format. The
> standard was QIC-36, although I think that Tandberg had a standard of their
> own.
>
Very likely. When thoses all came on the scene there were a number of
interfaces and encoding schemes. I was not involved in any of the politics
but QIC ended up as the encoding standard and SCSI the interface
IIRC the first QIC both Masscomp and Apollo used was QIC-36 via a SCSI
converter board SCS made for both of us. I don’t think Sun used it. Later
Archive and I think Wangtek made SCSI interface standard on the drives.
> I was wrong about the 9-track versus 7, the TC05/sentinel combination
> writes 11 tracks! The standard 1/4' cartridge media use QIC24, which
> specifies 9 tracks. I just knew it was not 9!
>
It also means it was not a QIC standard as I don’t believe they had one
between QIC-24-DC and QIC-120-DC. Which I would think means that if this
tape came from a TK25 I doubt either Steve or my drives will read it -
he’ll need to find someone with a TK25 - which I have never seen
personally.
> That's all I know!
>
fair enough
Clem_._,_._,_
>
I've got an exciting piece of hardware to pair with the VT100 I recently got, a Western Electric Dataphone 300. The various status lights and tests seem to work, and the necessary cabling is in place as far as the unit is concerned. However, it did not come with the accompanying telephone. I believe but can't verify yet that the expected telephone is or resembles a *565HK(M) series telephone, the ones with one red and five clear buttons along the bottom, otherwise resembling a standard WECo telephone.
Pictured: http://www.classicrotaryphones.com/forum/index.php?action=dlattach;attach=4…
Thus far I've found myself confused on the wiring expectations. There is a power line going into a small DC brick, one DB-25 port on the back terminating in a female 25-pair amphenol cable, and another DB-25 port with a ribbon extension plugged in. My assumptions thus far have been the amphenol plugs into a *565HK(M) or similar series telephone and the DB-25 then plugs into the serial interface of whichever end of the connection it represents. However, while this is all fine and dandy, it's missing one important part...a connection to the outside world. I've found no documentation describing this yet, although a few pictures from auctions that included a telephone seemed to have a standard telephone cable also coming out of the back of the telephone terminating in either a 6 or 8-conductor modular plug. The pictures were too low-res to tell which.
Would anyone happen to know anything concrete about the wiring situation with these, or some documentation hints, as I've tried some general web searches for documentation concerning Dataphone 300 and the 103J Data Set configuration and haven't turned up wiring-specific information. If nothing else I might just tap different places on the network block of the 2565HKM I've got plugged into it and see if anything resembling a telephone signal pops up when running some serial noise in at an appropriate baud. My fear is that the wiring differences extend beyond the tap to the CO/PBX line and that there are different wiring expectations in the 25-pair as well, this and my other appropriate telephone are both 1A2 wired I believe, still working on that KSU...
Any help is much appreciated, lotsa little details in these sorts of things, but once I get it working I intend to do some documentation and teardown photos. I don't want to take it apart yet and run the risk of doing something irreversible. I want to make sure it gets a chance to serve up some serial chit chat as weird telephone noises.
- Matt G.
FYI: Tim was Mr. 36-bit kernel and I/O system until he moved to the Vax and
later Alpha (and Intel).
The CMU device he refers is was the XGP and was a Xerox long-distance fax
(LDX). Stanford and MIT would get them too, shortly thereafter.
---------- Forwarded message ---------
From: Timothe Litt
Date: Thu, Dec 21, 2023 at 1:52 PM
Subject: Re: Fwd: [COFF] IBM 1403 line printer on DEC computers?
To: Clem Cole
I don't recall ever seeing a 1403 on a DECsystem-10 or DECSYSTEM-20. I
suppose someone could have connected one to a systems concepts channel...
or the DX20 Massbus -> IBM MUX/SEL channel used for the STC (TU70/1/2)
tape and disk (RP20=STC 8650) disk drives. (A KMC11-based device.) Not
sure why anyone would.
Most of the DEC printers on the -10/20 were Dataproducts buy-outs, and were
quite competent. 1,000 - 1,250 LPM. Earlier, we also bought from MDS and
Analex; good performance (1,000LPM), but needed more TLC from FS. The
majority were drum printers; the LP25 was a band printer, and lighter duty
(~300LPM).
Traditionally, we had long-line interfaces to allow all the dust and mess
to be located outside the machine room. Despite filters, dust doesn't go
well with removable disk packs. ANF-10 (and eventually DECnet) remote
stations provided distributed printing.
CMU had a custom interface to some XeroX printer - that begat Scribe.
The LN01 brought laser printing - light duty, but was nice for those
endless status reports and presentations. I think the guts were Canon -
but in any case a Japanese buyout. Postscript. Networked.
For high volume printing internally, we used XeroX laser printers when they
became available. Not what you'd think of today - these are huge,
high-volume devices. Bigger than the commercial copiers you'd see in print
shops. I(Perhaps interestingly, internally they used PDP-11s running
11M.) Networked, not direct attach. They also were popular in IBM shops.
We eventually released the software to drive them (DQS) as part of GALAXY.
The TU7x were solid drives - enough so that the SDC used them for making
distribution tapes. The copy software managed to keep 8 drives spinning at
125/200 ips - which was non-trivial on TOPS-20.
The DX20/TX0{2,3}/TU7x *was *eventually made available for VAX - IIRC as
part of the "Migration" strategy to keep customers when the -10/20 were
killed. I think CSS did the work on that for the LCG PL. Tapes only - I
don't think anyone wanted the disks by them - we had cheaper dual-porting
via the HSC/CI, and larger disks.
The biggest issue for printers on VAX was the omission of VFU support.
Kinda hard to print paychecks and custom forms without it - especially if
you're porting COBOL from the other 3-letter company. Technically, the
(Unibuas) LP20 could have been used, but wasn't. CSS eventually solved
that with some prodding from Aquarius - I pushed that among other high-end
I/O requirements.
On 21-Dec-23 12:29, Clem Cole wrote:
Tim - care to take a stab at this?
ᐧ
> From: Paul Winalski
> The 1403 attached to S/360/370 via a byte multiplexer channel ...
> The question is, did they have a way to attach the 1403 to any of their
> computer systems?
There's a thing called a DX11:
https://gunkies.org/wiki/DX11-B_System_360/370_Channel_to_PDP-11_Unibus_Int…
which attaches a "selector, multiplexer or block multiplexer channel" to a
UNIBUS machine, which sounds like it could support the "byte multiplexer
channel"?
The DX11 brochure only mentions that it can be "programmed to emulate a 2848,
2703 or 3705 control unit" - i.e. look like a peripheral to a IBM CPU;
whether it could look like an INM CPU to an IBM peripheral, I don't know.
(I'm too lazy to look at the documentation; it seems to be all there, though.)
Getting from the UNIBUS to the -10, there were off-the-shelf boxes for; the DL10 for
the KA10 and KI10 CPUs, and a DTE20 on a KL10.
It all probably needed some coding, though.
Noel
There's been a discussion recently on TUHS about the famous IBM 1403
line printer. It's strayed pretty far off-topic for TUHS so I'm
continuing the topic here in COFF.
DEC marketed its PDP-10 computer systems as their solution for
traditional raised-floor commercial data centers, competing directly
with IBM System 360/370. DEC OEMed a lot of data center peripherals
such as card readers/punches, line printers, 9-track magtape drives,
and disk drives for their computers, but their main focus was low cost
vs. heavy duty. Not really suitable for the data center world.
So DEC OEMed several high-end data center peripherals for use on big,
commercial PDP-10 computer systems. For example, the gold standard
for 9-track tape drives in the IBM world was tape drives from Storage
Technology Corporation (STC). DEC designed an IBM selector
channel-to-MASSBUS adapter that allowed one to attach STC tape drives
to a PDP-10. AFAIK this was never offered on the PDP-11 VAX, or any
other of DEC's computer lines. They had similar arrangements for
lookalikes for IBM high-performance disk drives.
Someone on TUHS recalled seeing an IBM 1403 or similar line printer on
a PDP-10 system. The IBM 1403 was certainly the gold standard for
line printers in the IBM world and was arguably the best impact line
printer ever made. It was still highly sought after in the 1970s,
long after the demise of the 1950s-era IBM 1400 computer system it was
designed to be a part of. Anyone considering a PDP-10 data center
solution would ask about line printers and, if they were from the IBM
world, would prefer a 1403.
The 1403 attached to S/360/370 via a byte multiplexer channel, so one
would need an adapter that looked like a byte multiplexer channel on
one end and could attach to one of DEC's controllers at the other end
(something UNIBUS-based, most likely).
We know DEC did this sort of thing for disks and tapes. The question
is, did they have a way to attach the 1403 to any of their computer
systems?
-Paul W.
> the first DEC machine with an IC processor was the -11/20, in 1970
Clem has reminded me that the first was the PDP-8/I-L (the second was a
cost-reduced version of the -I), from. The later, and much more common,
PDP-8/E-F-M, were contemporaneous with the -11/20.
Oh well, only two years; doesn't really affect my main point. Just about
'blink and you'll miss them'!
Noel
> From: Bakul Shah
> Now I'd probably call them kernel threads as they don't have a separate
> address space.
Makes sense. One query about stacks, and blocking, there. Do kernel threads,
in general, have per-thread stacks; so that they can block (and later resume
exactly where they were when they blocked)?
That was the thing that, I think, made kernel processes really attractive as
a kernel structuring tool; you get code ike this (from V6):
swap(rp->p_addr, a, rp->p_size, B_READ);
mfree(swapmap, (rp->p_size+7)/8, rp->p_addr);
The call to swap() blocks until the I/O operation is complete, whereupon that
call returns, and away one goes. Very clean and simple code.
Use of a kernel process probably makes the BSD pageout daemon code fairly
straightforward, too (well, as straightforward as anything done by Berzerkly
was :-).
Interestingly, other early systems don't seem to have thought of this
structuring technique. I assumed that Multics used a similar technique to
write 'dirty' pages out, to maintain a free list. However, when I looked in
the Multics Storage System Program Logic Manual:
http://www.bitsavers.org/pdf/honeywell/large_systems/multics/AN61A_storageS…
Multics just writes dirty pages as part of the page fault code: "This
starting of writes is performed by the subroutine claim_mod_core in
page_fault. This subroutine is invoked at the end of every page fault." (pg.
8-36, pg. 166 of the PDF.) (Which also increases the real-time delay to
complete dealing with a page fault.)
It makes sense to have a kernel process do this; having the page fault code
do it just makes that code more complicated. (The code in V6 to swap
processes in and out is beautifully simple.) But it's apparently only obvious
in retrospect (like many brilliant ideas :-).
Noel
So Lars Brinkhoff and I were chatting about daemons:
https://gunkies.org/wiki/Talk:Daemon
and I pointed out that in addition to 'standard' daemons (e.g. the printer
spooler daemon, email daemon, etc, etc) there are some other things that are
daemon-like, but are fundamentally different in major ways (explained later
below). I dubbed them 'system processes', but I'm wondering if ayone knows if
there is a standard term for them? (Or, failing that, if they have a
suggestion for a better name?)
Early UNIX is one of the first systems to have one (process 0, the "scheduling (swapping)
process"), but the CACM "The UNIX Time-Sharing System" paper:
https://people.eecs.berkeley.edu/~brewer/cs262/unix.pdf
doesn't even mention it, so no guidance there. Berkeley UNIX also has one,
mentioned in "Design and Implementation of the Berkeley Virtual Memory
Extensions to the UNIX Operating System":
http://roguelife.org/~fujita/COOKIES/HISTORY/3BSD/design.pdf
where it is called the "pageout daemon".("During system initialization, just
before the init process is created, the bootstrapping code creates process 2
which is known as the pageout daemon. It is this process that .. writ[es]
back modified pages. The process leaves its normal dormant state upon being
waken up due to the memory free list size dropping below an upper
threshold.") However, I think there are good reasons to dis-favour the term
'daemon' for them.
For one thing, typical daemons look (to the kernel) just like 'normal'
processes: their object code is kept in a file, and is loaded into the
daemon's process when it starts, using the same mechanism that 'normal'
processes use for loading their code; daemons are often started long after
the kernel itself is started, and there is usually not a special mechanism in
the kernel to start daemons (on early UNIXes, /etc/rc is run by the 'init'
process, not the kernel); daemons interact with the kernel through system
calls, just like 'ordinary' processes; the daemon's process runs in 'user'
CPU mode (using the same standard memory mapping mechanisms, just like
blah-blah).
'System processes' do none of these things: their object code is linked into
the monolithic kernel, and is thus loaded by the bootstrap; the kernel
contains special provision for starting the system process, which start as
the kernel is starting; they don't do system calls, just call kernel routines
directly; they run in kernel mode, using the same memory mapping as the
kernel itself; etc, etc.
Another important point is that system processes are highly intertwined with
the operation of the kernel; without the system process(es) operating
correctly, the operation of the system will quickly grind to a halt. The loss
of ordinary' daemons is usually not fatal; if the email daemon dies, the
system will keep running indefinitely. Not so, for the swapping process, or
the pageout daemon
Anyway, is there a standard term for these things? If not, a better name than
'system process'?
Noel
For the benefit of Old Farts around here, I'd like to share the good
word that an ITS 138 listing from 1967 has been discovered. A group of
volunteers is busy transcribing the photographed pages to text.
Information and link to the data:
https://gunkies.org/wiki/ITS_138
This version is basically what ITS first looked like when it went into
operation at the MIT AI lab. It's deliciously arcane and primitive.
Mass storage is on four DECtape drives, no disk here. Users stations
consist of five teletypes and four GE Datanet 760 CRT consoles (46
colums, 26 lines). The number of system calls is a tiny subset of what
would be available later.
There are more listings from 1967-1969 for DDT, TECO, LISP, etc. Since
they are fan-fold listings, scanning is a bit tricky, so a more labor-
intensive photographing method is used.
Hello everyone, I was wondering if anyone is aware of any surviving technical diagrams/schematics for the WECo 321EB or WECo 321DS WE32x00 development systems? Bitsavers has an AT&T Data Book from 1987 detailing pin maps, registers, etc. of 32xxx family ICs and then another earlier manual from 1985 that seems to be more focused on a technical overview of the CPU specifically. Both have photographs and surface level block diagrams, but nothing showing individual connections, which bus leads went where, etc. While the descriptions should be enough, diagrams are always helpful.
In any case, I've recently ordered a 32100 CPU and 32101 MMU I saw sitting on eBay to see what I can do with some breadboarding and some DRAM/DMA controllers from other vendors, was thinking of referring to any available design schematics of the 321 development stuff for pointers on integrations. Either way, i'm glad the data books on the hardware have been preserved, that gives me a leg up.
Thanks for any insights!
- Matt G.
Good day everyone, I thought I'd share a new project I've been working on since it is somewhat relevant to old and obscure computing stuff that hasn't gotten a lot of light shed on it.
https://gitlab.com/segaloco/doki
After the link is an in-progress disassembly of Yume Kojo: Doki Doki Panic for the Famicom Disk System, known better in the west as the engine basis for Super Mario Bros. 2 for the NES (the one with 4 playable characters, pick-and-throw radishes, etc.)
What inspired me to start on this project is the Famicom Disk System is painfully under-documented, and what is out there is pretty patchy. Unlike with its parent console, no 1st party development documentation has been archived concerning the Disk System, so all that is known about its programming interfaces have been determined from disassemblies of boot ROMs and bits and pieces of titles over the years. The system is just that, a disk drive that connects to the Famicom via a special adapter that provides some RAM, additional sound functionality, and some handling for matters typically controlled by the cartridge (background scroll-plane mirroring and saving particularly.) The physical disk format is based on Mitsumi's QuickDisk format, albeit with the casing extended in one dimension as to provide physical security grooves that, if not present, will prevent the inserted disk from booting. The hardware includes a permanently-resident boot ROM which maps to 0xE000-0xFFFF (and therefore provides the 6502 vectors). This boot ROM in turn loads any files from the disk that match a specified pattern in the header to header-defined memory ranges and then acts on a secondary vector table at 0xDFFA (really 0xDFF6, the disk system allows three separate NMI vectors which are selected from by a device register.) The whole of the standard Famicom programming environment applies, although the Disk System adds an additional bank of device registers in a reserved memory area and exposes a number of "syscalls" (really just endpoints in the 0xE000-0xFFFF range, it's unknown at present to what degree these entries/addresses were documented to developers.)
I had to solve a few interesting challenges in this process since this particular area gets so little attention. First, I put together a utility and supporting library to extrapolate info from the disk format. Luckily the header has been (mostly) documented, and I was able to document a few consistencies between disks to fill in a few of the parts that weren't as well documented. In any case, the results of that exercise are here: https://gitlab.com/segaloco/fdschunk. One of the more interesting matters is that the disk creation and write dates are stored not only in BCD, but the year is not always Gregorian. Rather, many titles reflect instead the Japanese period at the time the title was released. For instance, the Doki Doki Panic image I'm using as a reference is dated (YY/MM/DD) "61/11/26" which is preposterous, the Famicom was launched in 1983, but applying this knowledge of the Showa period, the date is really "86/11/26" which makes much more sense. This is one of those things I run into studying Japanese computing history time to time, I'm sure the same applies to earlier computing in other non-western countries. We're actually headed for a "2025-problem" with this time-keeping as that is when the Showa calendar rolls over. No ROMs have been recovered from disk writer kiosks employed by Nintendo in the 80s, so it is unknown what official hardware which applies these timestamps does when that counter rolls over. I've just made the assumption that it should roll back to 00, but there is no present way to prove this. The 6502 implementation in the Famicom (the Ricoh 2A03) omitted the 6502 BCD mode, so this was likely handled either in software or perhaps a microcontroller ROM down inside the disk drives themselves.
I then had to solve the complementary problem, how do I put a disk image back together according to specs that aren't currently accessible. Well, to do that, I first chopped the headers off of every first-party Nintendo image I had in my archive and compared them in a table. I diverted them into two groups: pristine images that represent original pressings in a Nintendo facility and "dirty" images that represent a rewrite of a disk at one of the disk kiosks (mind you, Nintendo distributed games both ways, you could buy a packaged copy or you could bring a rewritable disk to a kiosk and "download" a new game.) My criterion for categorization was whether the disk create and modify times were equal or not. This allowed me to get a pretty good picture of what headers getting pumped out of the factory look like, and how they change when the disk is touched by a writer kiosk. I then took the former configuration and wrote a couple tools to consume a very spartan description of the variable pieces and produce the necessary images: https://gitlab.com/segaloco/misc/-/tree/master/fds. These tools, bintofdf and fdtc, apply a single file header to a disk file and create a "superblock" for a disk side respectively. I don't know what the formal terms are, they may be lost to time, but superblock hopefully gets the point across, albeit it's not an exact analog to UNIX filesystems. Frankly I can't find anything regarding what filesystem this might be based on, if at all, or if it is an entirely Nintendo-derived format. In any case, luckily the header describing a file is self-contained on that file, and then the superblock only needs to know how many files are present, so the two steps can be done independently. The result is a disk image, stamped with the current Showa BCD date, that is capable of booting on the system. The only thing I don't add that "pure" disks contain are CRCs of the files. On a physical disk, these header blocks also contain CRCs of the data they describe, these, by convention, are omitted from disk dumps. I'm actually not entirely sure why, but I imagine emulator writers just omit the CRC check as well, so it doesn't matter to folks just looking to play a game.
Finally, there's the matter of disparate files which may or may not necessarily be sitting in memory at runtime. Luckily the linker script setup in cc65 (the compiler suite I'm using) is pretty robust, and just like my Dragon Quest disassembly (which is made up of swappable banks) I was able to use the linker system to produce all of the necessary files in isolation, rather than having to get creative with orgs and compilation order to clobber something together that worked. This allows the code to be broken down into its logical structure rather than just treating a whole disk side as if it was one big binary with .org commands all over the place.
Anywho, I don't intend on a rolling update to this email or anything, but if this is something that piques anyone's interest and you'd like to know more, feel free to shoot me a direct reply. I'd be especially interested in any stories or info regarding Mitsumi QuickDisk, as one possibility is that Nintendo's format is derived from something of their own, with reserved/undefined fields redefined for Nintendo's purposes. That said, it's just a magnetic disk, I would be surprised if a single filesystem was enforced in all implementations.
Thanks for following along!
- Matt G.
P.S. As always contributions to anything I'm working on are welcome and encouraged, so if you have any input and have a GitLab account, feel free to open an issue, fork and raise a PR, etc.
> From: Dan Cross
> This is long, but very interesting: https://spectrum.ieee.org/xerox-parc
That is _very_ good, and I too recommend it.
Irritatingly, for such an otherwise-excellent piece, it contains two glaring,
minor errors: "information-processing techniques office" should be
'Information Processing Techniques Office' (its formal name; it's not a
description); "the 1,103 dynamic memory chips used in the MAXC design" -
that's the Intel 1103 chip.
> Markov's book, "What the Dormouse Said" ... goes into great detail
> about the interplay between Engelbart's group at SRI and PARC. It's a
> very interesting read; highly recommended.
It is a good book; it goes a long way into explaining why the now-dominant form
of computer user experience appeared on the West coast, ad not the East.
One big gripe about it; it doesn't give enough space to Licklider, who more
than anyone had the idea that computers were a tool for _all_ information
(for everyone, from all walks of life), not just number crunching (for
scientists and engineers). Everyone and everything in Dormouse is a
descendant of his. Still, we have Mitchell Waldrop's "Dream Machine", which
does an excellent job of telling his story.
(Personal note: I am sad and ashamed to admit that for several years I had
the office literally right next door next to his - and I had no idea who he
was! This is kind of like a young physicist having the office right next door
next to Einstein, and not knowing who _he_ was! I can only say that the
senior people in my group didn't make much of Lick; which didn't help.)
Still, get "Dream Machine".
Noel
> From: Larry McVoy
> And the mouse unless my boomer memory fails me.
I think it might have; I'm pretty sure the first mice were done by
Engelbart's group at ARC (but I'm too lazy to check). ISTR that they were
used in the MOAD.
PARC's contribution to mice was the first decent mouse. I saw an ARC mouse at
MIT (before we got our Altos), and it was both large, and not smooth to use;
it was a medium-sized box (still one hand, though) with two large wheels
(with axes 90 degrees apart), so moving it sideways, you had to drag the
up/down sheel sideways (and vice versa).
PARC'S design (the inventor is known; I've forgetten his name) with the large
ball bearing, rotation of which was detected by two sensore, was _much_
better, and remained the standard until the invention of the optical mouse
(which was superior because the ball mouse picked up dirt, and had to be
cleaned out regularly).
PARC's other big contribution was the whole network-centric computing model,
with servers and workstations (the Alto). Hints of both of those existed
before, but PARC's unified implementation of both (and in a way that made
them cheap enough to deploy them widely) was a huge jump forward.
Although 'personal computers' had a long (if now poorly remembered) history
at that point (including the LINC, and ARC's station), the Alto showed what
could be done when you added a bit-mapped display to which the CPU had direct
access, and deployed a group of them in a network/server environment; having
so much computing power available, on an individual basis, that you could
'light your cigar with computes' radcally changed everything.
Noel
An Old Farts Question, but answers unrestricted :)
In the late 1990’s I inherited a web hosting site running a number of 300Mhz SPARC SUNs.
Probably 32-bit, didn’t notice then :)
Some were multi-CPU’s + asymmetric memory [ non-uniform memory access (CC-NUMA) ]
We had RAID-5 on a few, probably a hardware controller with Fibre Channel SCSI disks.
LAN ports 100Mbps, IIRC. Don’t think we had 1Gbps switches.
Can’t recall how much RAM or the size of the RAID-5 volume.
I managed to borrow from SUN a couple of drives for 2-3 months & filled all the drive bays for ‘busy time'.
With 300MB drives, at most we had a few GB.
Don’t know the cost of the original hardware - high six or seven figures.
A single additional board with extra CPU’s & DRAM for one machine was A$250k, IIRC.
TB storage & zero ’seek & latency’ with SSD are now cheap and plentiful,
even using “All Flash” Enterprise Storage & SAN’s.
Storage system performance is now 1000x or more, even for cheap M.2 SSD.
Pre-2000, a ‘large’ RAID was GB.
Where did all this new ‘important’ data come from?
Raw CPU speed was once the Prime System Metric, based on an assumption of ‘balanced’ systems.
IO performance and Memory size needed to match the CPU throughput for a desired workload,
not be the “Rate Limiting Step”, because CPU’s were very expensive and their capacity couldn’t be ‘wasted’.
I looked at specs/ benchmarks of the latest R-Pi 5 and it might be ~10,000x cheaper than the SUN machines
while maybe 10x faster.
I never knew the webpages/ second my machines provided,
I had to focus on Application throughput & optimising that :-/
I was wondering if anyone on-list has tracked the Cost/ Performance of systems over the last 25 years.
With Unix / Linux, we really can do “Apples & Apples” comparisons now.
I haven’t done the obvious Internet searches, any comments & pointers appreciated.
============
Raspberry Pi 5 revealed, and it should satisfy your need for speed
No longer super-cheap, but boasts better graphics and swifter storage
<https://www.theregister.com/2023/09/28/raspberry_pi_5_revealed/>
~$150 + PSU & case, cooler.
Raspberry Pi 5 | Review, Performance & Benchmarks
<https://core-electronics.com.au/guides/raspberry-pi/raspberry-pi-5-review-p…>
Benchmark Table
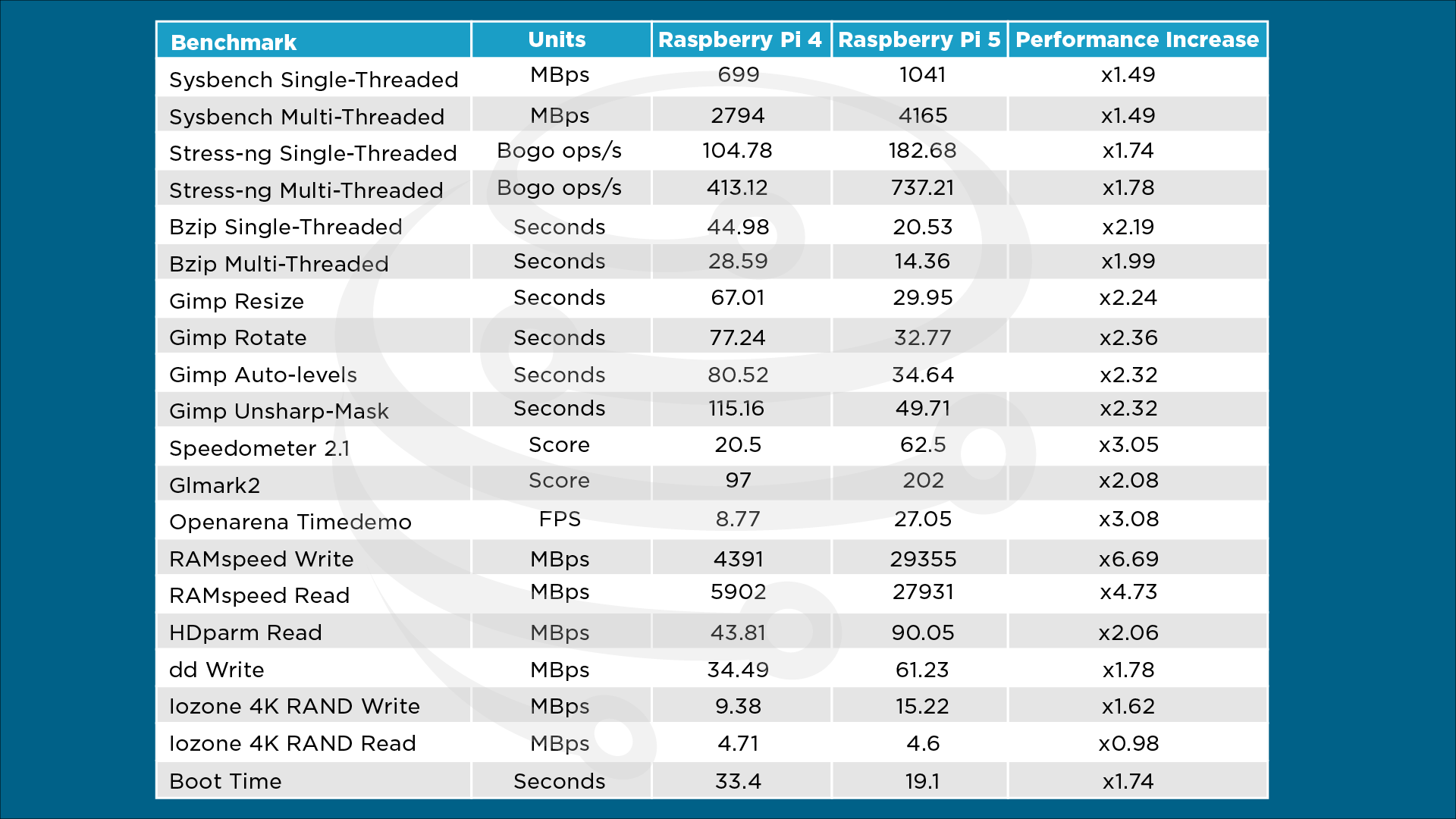
<https://core-electronics.com.au/media/wysiwyg/tutorials/Jaryd/pi-les-go/Ben…>
[ the IO performance is probably to SD-Card ]
64 bit, 4-core, 2.4Ghz,
1GB / 2GB / 4GB / 8GB DRAM
800MHz VideoCore GPU = 2x 4K displays @ 60Hz
single-lane PCI Express 2.0 [ for M.2 SSD ]
2x four-lane 1.5Gbps MIPI transceivers [ camera & display ]
2x USB 3.0 ports,
"RP1 chip reportedly allows for simultaneous 5-gigabit throughput on both the USB 3.0s now."
2x USB 2.0 ports,
1x Gigabit Ethernet,
27W USB-C Power + active cooler (fan)
============
--
Steve Jenkin, IT Systems and Design
0412 786 915 (+61 412 786 915)
PO Box 38, Kippax ACT 2615, AUSTRALIA
mailto:sjenkin@canb.auug.org.au http://members.tip.net.au/~sjenkin
Bell Labs Dept 1127 / CSRC qualifies as “Very High Performing” to me (is there a better name?)
Before that, John von Neumann and his team were outstanding in the field.
DARPA, under Licklider then Bob Taylor & Ivan Sutherland and more people I don’t know,
went on to fund game-changing technologies, such TCP/IP, including over Wireless and Satellite links.
Engelbart’s Augmentation Research Centre was funded by DARPA, producing NLS, the "oN-Line System”.
Taylor founded Xerox PARC, taking many of Engelbart’s team when the ARC closed.
PARC invented so many things, it’s hard to list…
Ethernet, Laser printers, GUI & Windowing System, Object Oriented (? good ?), what became ’the PC'
Evans & Sutherland similarly defined the world of Graphics for many years.
MIPS Inc created the first commercial RISC processor with a small team, pioneering using 3rd Party “Fabs”.
At 200 Mhz, it was twice the speed of competitors.
Seymour Cray and his small team built (with ECL) the fastest computers for a decade.
I heard that CDC produced a large, slow Operating System, so Cray went and wrote a better one “in a weekend”.
A hardware & software whizz.
I’ve not intended to leave any of the "Hot Spots” out.
While MIT did produce some good stuff, I don’t see it as “very high performing”.
Happy to hear disconfirming opinion.
What does this has to do with now?
Google, AWS and Space-X have redefined the world of computing / space in the last 10-15 years.
They've become High Performing “Hot Spots”, building technology & systems that out-perform everyone else.
Again, not intentionally leaving out people, just what I know without deeply researching.
================
Is this a topic that’s been well addressed? If so, sorry for wasting time.
Otherwise, would appreicate pointers & comments, especially if anyone has created a ‘definitive’ list,
which would imply some criteria for admission.
================
--
Steve Jenkin, IT Systems and Design
0412 786 915 (+61 412 786 915)
PO Box 38, Kippax ACT 2615, AUSTRALIA
mailto:sjenkin@canb.auug.org.au http://members.tip.net.au/~sjenkin
I just realised that in HP-UX there are lots of filesets with various
language messages files and manpages (japanese, korean and chinese).
Normally I don't install these. Therefore I also have no idea what the
format is
If you're interested I could install a few and mail you a bundle. Just let
me know.
Take care,
uncle rubl
--
The more I learn the better I understand I know nothing.
Subject doesn't roll off the tongue like the song, but hey, I got a random thought today and I'd be interested in experiences. I get where this could be a little...controversial, so no pressure to reply publicly or at all.
Was it firmly held lore from the earliest days to keep the air as clean as possible in computer rooms in the earlier decades of computing? What has me asking is I've seen before photos from years past in R&D and laboratory settings where whoever is being photographed is happy dragging away on a cigarette (or...) whilst surrounded by all sorts of tools, maybe chemicals, who knows. It was a simpler time, and rightfully so those sorts of lax attitudes have diminished for the sake of safety. Still I wonder, was the situation the same in computing as photographic evidence has suggested it is in other such technical settings? Did you ever have to deal with a smoked out server room that *wasn't* because of thermal issues with the machinery?
I hope this question is fine by the way, it's very not tech focused but I also have a lot of interest in the cultural shifts in our communities over the years. Thanks as always folks for being a part of one of the greatest stories still being told!
- Matt G.
Good morning, I am going to pick up a few Japanese computing books to get more familiar with translating technical literature and figured I'd see if anyone here has any of these before I go buying from randos on eBay (Not sure all of these exist in Japanese):
The C Programming Language (Either Edition)
The C++ Programming Language
Any AT&T/USL System V Docs
The UNIX System (Bourne)
John Lions's Commentary
Any Hardware Docs from Japanese shops (Sony, NEC, Sharp, JVC, etc) that have English counterparts (e.g. MSX architecture docs, PC-*8 hardware stuff)
Thanks all!
- Matt G.
P.S. Even less likely but any of the above in Chinese I would be interested in as well. Many Kanji and Hanzi overlap in meaning so while it may be like trying to read Chaucer with no knowledge of antiquated English, translation between Hanzi and English may help the Kanji situation along too.









{kind=link}
{kind=link}
{kind=link}