Good day everyone, I thought I'd share a new project I've been working on since it is somewhat relevant to old and obscure computing stuff that hasn't gotten a lot of light shed on it.
https://gitlab.com/segaloco/doki
After the link is an in-progress disassembly of Yume Kojo: Doki Doki Panic for the Famicom Disk System, known better in the west as the engine basis for Super Mario Bros. 2 for the NES (the one with 4 playable characters, pick-and-throw radishes, etc.)
What inspired me to start on this project is the Famicom Disk System is painfully under-documented, and what is out there is pretty patchy. Unlike with its parent console, no 1st party development documentation has been archived concerning the Disk System, so all that is known about its programming interfaces have been determined from disassemblies of boot ROMs and bits and pieces of titles over the years. The system is just that, a disk drive that connects to the Famicom via a special adapter that provides some RAM, additional sound functionality, and some handling for matters typically controlled by the cartridge (background scroll-plane mirroring and saving particularly.) The physical disk format is based on Mitsumi's QuickDisk format, albeit with the casing extended in one dimension as to provide physical security grooves that, if not present, will prevent the inserted disk from booting. The hardware includes a permanently-resident boot ROM which maps to 0xE000-0xFFFF (and therefore provides the 6502 vectors). This boot ROM in turn loads any files from the disk that match a specified pattern in the header to header-defined memory ranges and then acts on a secondary vector table at 0xDFFA (really 0xDFF6, the disk system allows three separate NMI vectors which are selected from by a device register.) The whole of the standard Famicom programming environment applies, although the Disk System adds an additional bank of device registers in a reserved memory area and exposes a number of "syscalls" (really just endpoints in the 0xE000-0xFFFF range, it's unknown at present to what degree these entries/addresses were documented to developers.)
I had to solve a few interesting challenges in this process since this particular area gets so little attention. First, I put together a utility and supporting library to extrapolate info from the disk format. Luckily the header has been (mostly) documented, and I was able to document a few consistencies between disks to fill in a few of the parts that weren't as well documented. In any case, the results of that exercise are here: https://gitlab.com/segaloco/fdschunk. One of the more interesting matters is that the disk creation and write dates are stored not only in BCD, but the year is not always Gregorian. Rather, many titles reflect instead the Japanese period at the time the title was released. For instance, the Doki Doki Panic image I'm using as a reference is dated (YY/MM/DD) "61/11/26" which is preposterous, the Famicom was launched in 1983, but applying this knowledge of the Showa period, the date is really "86/11/26" which makes much more sense. This is one of those things I run into studying Japanese computing history time to time, I'm sure the same applies to earlier computing in other non-western countries. We're actually headed for a "2025-problem" with this time-keeping as that is when the Showa calendar rolls over. No ROMs have been recovered from disk writer kiosks employed by Nintendo in the 80s, so it is unknown what official hardware which applies these timestamps does when that counter rolls over. I've just made the assumption that it should roll back to 00, but there is no present way to prove this. The 6502 implementation in the Famicom (the Ricoh 2A03) omitted the 6502 BCD mode, so this was likely handled either in software or perhaps a microcontroller ROM down inside the disk drives themselves.
I then had to solve the complementary problem, how do I put a disk image back together according to specs that aren't currently accessible. Well, to do that, I first chopped the headers off of every first-party Nintendo image I had in my archive and compared them in a table. I diverted them into two groups: pristine images that represent original pressings in a Nintendo facility and "dirty" images that represent a rewrite of a disk at one of the disk kiosks (mind you, Nintendo distributed games both ways, you could buy a packaged copy or you could bring a rewritable disk to a kiosk and "download" a new game.) My criterion for categorization was whether the disk create and modify times were equal or not. This allowed me to get a pretty good picture of what headers getting pumped out of the factory look like, and how they change when the disk is touched by a writer kiosk. I then took the former configuration and wrote a couple tools to consume a very spartan description of the variable pieces and produce the necessary images: https://gitlab.com/segaloco/misc/-/tree/master/fds. These tools, bintofdf and fdtc, apply a single file header to a disk file and create a "superblock" for a disk side respectively. I don't know what the formal terms are, they may be lost to time, but superblock hopefully gets the point across, albeit it's not an exact analog to UNIX filesystems. Frankly I can't find anything regarding what filesystem this might be based on, if at all, or if it is an entirely Nintendo-derived format. In any case, luckily the header describing a file is self-contained on that file, and then the superblock only needs to know how many files are present, so the two steps can be done independently. The result is a disk image, stamped with the current Showa BCD date, that is capable of booting on the system. The only thing I don't add that "pure" disks contain are CRCs of the files. On a physical disk, these header blocks also contain CRCs of the data they describe, these, by convention, are omitted from disk dumps. I'm actually not entirely sure why, but I imagine emulator writers just omit the CRC check as well, so it doesn't matter to folks just looking to play a game.
Finally, there's the matter of disparate files which may or may not necessarily be sitting in memory at runtime. Luckily the linker script setup in cc65 (the compiler suite I'm using) is pretty robust, and just like my Dragon Quest disassembly (which is made up of swappable banks) I was able to use the linker system to produce all of the necessary files in isolation, rather than having to get creative with orgs and compilation order to clobber something together that worked. This allows the code to be broken down into its logical structure rather than just treating a whole disk side as if it was one big binary with .org commands all over the place.
Anywho, I don't intend on a rolling update to this email or anything, but if this is something that piques anyone's interest and you'd like to know more, feel free to shoot me a direct reply. I'd be especially interested in any stories or info regarding Mitsumi QuickDisk, as one possibility is that Nintendo's format is derived from something of their own, with reserved/undefined fields redefined for Nintendo's purposes. That said, it's just a magnetic disk, I would be surprised if a single filesystem was enforced in all implementations.
Thanks for following along!
- Matt G.
P.S. As always contributions to anything I'm working on are welcome and encouraged, so if you have any input and have a GitLab account, feel free to open an issue, fork and raise a PR, etc.
> From: Dan Cross
> This is long, but very interesting: https://spectrum.ieee.org/xerox-parc
That is _very_ good, and I too recommend it.
Irritatingly, for such an otherwise-excellent piece, it contains two glaring,
minor errors: "information-processing techniques office" should be
'Information Processing Techniques Office' (its formal name; it's not a
description); "the 1,103 dynamic memory chips used in the MAXC design" -
that's the Intel 1103 chip.
> Markov's book, "What the Dormouse Said" ... goes into great detail
> about the interplay between Engelbart's group at SRI and PARC. It's a
> very interesting read; highly recommended.
It is a good book; it goes a long way into explaining why the now-dominant form
of computer user experience appeared on the West coast, ad not the East.
One big gripe about it; it doesn't give enough space to Licklider, who more
than anyone had the idea that computers were a tool for _all_ information
(for everyone, from all walks of life), not just number crunching (for
scientists and engineers). Everyone and everything in Dormouse is a
descendant of his. Still, we have Mitchell Waldrop's "Dream Machine", which
does an excellent job of telling his story.
(Personal note: I am sad and ashamed to admit that for several years I had
the office literally right next door next to his - and I had no idea who he
was! This is kind of like a young physicist having the office right next door
next to Einstein, and not knowing who _he_ was! I can only say that the
senior people in my group didn't make much of Lick; which didn't help.)
Still, get "Dream Machine".
Noel
> From: Larry McVoy
> And the mouse unless my boomer memory fails me.
I think it might have; I'm pretty sure the first mice were done by
Engelbart's group at ARC (but I'm too lazy to check). ISTR that they were
used in the MOAD.
PARC's contribution to mice was the first decent mouse. I saw an ARC mouse at
MIT (before we got our Altos), and it was both large, and not smooth to use;
it was a medium-sized box (still one hand, though) with two large wheels
(with axes 90 degrees apart), so moving it sideways, you had to drag the
up/down sheel sideways (and vice versa).
PARC'S design (the inventor is known; I've forgetten his name) with the large
ball bearing, rotation of which was detected by two sensore, was _much_
better, and remained the standard until the invention of the optical mouse
(which was superior because the ball mouse picked up dirt, and had to be
cleaned out regularly).
PARC's other big contribution was the whole network-centric computing model,
with servers and workstations (the Alto). Hints of both of those existed
before, but PARC's unified implementation of both (and in a way that made
them cheap enough to deploy them widely) was a huge jump forward.
Although 'personal computers' had a long (if now poorly remembered) history
at that point (including the LINC, and ARC's station), the Alto showed what
could be done when you added a bit-mapped display to which the CPU had direct
access, and deployed a group of them in a network/server environment; having
so much computing power available, on an individual basis, that you could
'light your cigar with computes' radcally changed everything.
Noel
An Old Farts Question, but answers unrestricted :)
In the late 1990’s I inherited a web hosting site running a number of 300Mhz SPARC SUNs.
Probably 32-bit, didn’t notice then :)
Some were multi-CPU’s + asymmetric memory [ non-uniform memory access (CC-NUMA) ]
We had RAID-5 on a few, probably a hardware controller with Fibre Channel SCSI disks.
LAN ports 100Mbps, IIRC. Don’t think we had 1Gbps switches.
Can’t recall how much RAM or the size of the RAID-5 volume.
I managed to borrow from SUN a couple of drives for 2-3 months & filled all the drive bays for ‘busy time'.
With 300MB drives, at most we had a few GB.
Don’t know the cost of the original hardware - high six or seven figures.
A single additional board with extra CPU’s & DRAM for one machine was A$250k, IIRC.
TB storage & zero ’seek & latency’ with SSD are now cheap and plentiful,
even using “All Flash” Enterprise Storage & SAN’s.
Storage system performance is now 1000x or more, even for cheap M.2 SSD.
Pre-2000, a ‘large’ RAID was GB.
Where did all this new ‘important’ data come from?
Raw CPU speed was once the Prime System Metric, based on an assumption of ‘balanced’ systems.
IO performance and Memory size needed to match the CPU throughput for a desired workload,
not be the “Rate Limiting Step”, because CPU’s were very expensive and their capacity couldn’t be ‘wasted’.
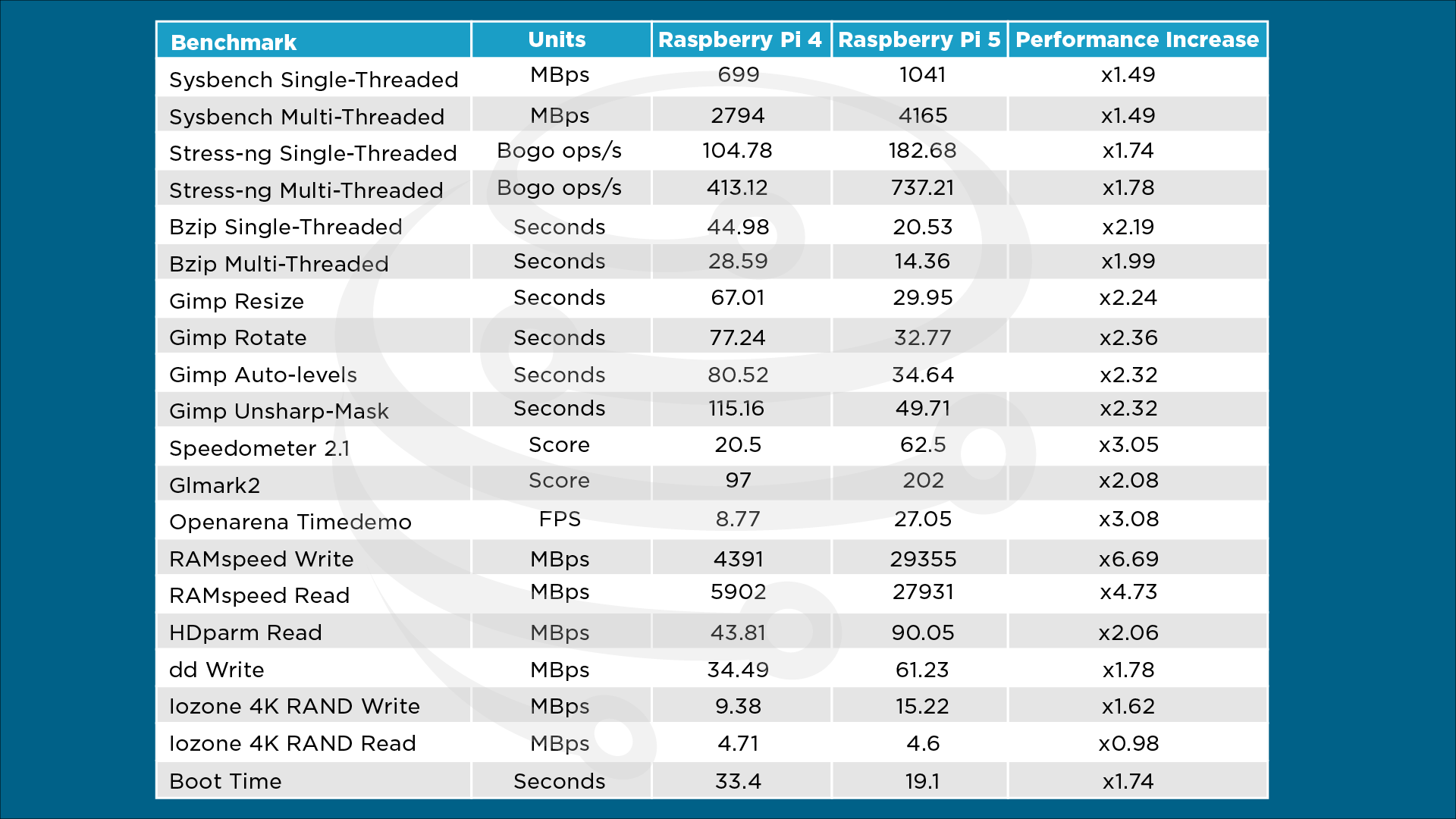
I looked at specs/ benchmarks of the latest R-Pi 5 and it might be ~10,000x cheaper than the SUN machines
while maybe 10x faster.
I never knew the webpages/ second my machines provided,
I had to focus on Application throughput & optimising that :-/
I was wondering if anyone on-list has tracked the Cost/ Performance of systems over the last 25 years.
With Unix / Linux, we really can do “Apples & Apples” comparisons now.
I haven’t done the obvious Internet searches, any comments & pointers appreciated.
============
Raspberry Pi 5 revealed, and it should satisfy your need for speed
No longer super-cheap, but boasts better graphics and swifter storage
<https://www.theregister.com/2023/09/28/raspberry_pi_5_revealed/>
~$150 + PSU & case, cooler.
Raspberry Pi 5 | Review, Performance & Benchmarks
<https://core-electronics.com.au/guides/raspberry-pi/raspberry-pi-5-review-p…>
Benchmark Table
<https://core-electronics.com.au/media/wysiwyg/tutorials/Jaryd/pi-les-go/Ben…>
[ the IO performance is probably to SD-Card ]
64 bit, 4-core, 2.4Ghz,
1GB / 2GB / 4GB / 8GB DRAM
800MHz VideoCore GPU = 2x 4K displays @ 60Hz
single-lane PCI Express 2.0 [ for M.2 SSD ]
2x four-lane 1.5Gbps MIPI transceivers [ camera & display ]
2x USB 3.0 ports,
"RP1 chip reportedly allows for simultaneous 5-gigabit throughput on both the USB 3.0s now."
2x USB 2.0 ports,
1x Gigabit Ethernet,
27W USB-C Power + active cooler (fan)
============
--
Steve Jenkin, IT Systems and Design
0412 786 915 (+61 412 786 915)
PO Box 38, Kippax ACT 2615, AUSTRALIA
mailto:sjenkin@canb.auug.org.au http://members.tip.net.au/~sjenkin
Bell Labs Dept 1127 / CSRC qualifies as “Very High Performing” to me (is there a better name?)
Before that, John von Neumann and his team were outstanding in the field.
DARPA, under Licklider then Bob Taylor & Ivan Sutherland and more people I don’t know,
went on to fund game-changing technologies, such TCP/IP, including over Wireless and Satellite links.
Engelbart’s Augmentation Research Centre was funded by DARPA, producing NLS, the "oN-Line System”.
Taylor founded Xerox PARC, taking many of Engelbart’s team when the ARC closed.
PARC invented so many things, it’s hard to list…
Ethernet, Laser printers, GUI & Windowing System, Object Oriented (? good ?), what became ’the PC'
Evans & Sutherland similarly defined the world of Graphics for many years.
MIPS Inc created the first commercial RISC processor with a small team, pioneering using 3rd Party “Fabs”.
At 200 Mhz, it was twice the speed of competitors.
Seymour Cray and his small team built (with ECL) the fastest computers for a decade.
I heard that CDC produced a large, slow Operating System, so Cray went and wrote a better one “in a weekend”.
A hardware & software whizz.
I’ve not intended to leave any of the "Hot Spots” out.
While MIT did produce some good stuff, I don’t see it as “very high performing”.
Happy to hear disconfirming opinion.
What does this has to do with now?
Google, AWS and Space-X have redefined the world of computing / space in the last 10-15 years.
They've become High Performing “Hot Spots”, building technology & systems that out-perform everyone else.
Again, not intentionally leaving out people, just what I know without deeply researching.
================
Is this a topic that’s been well addressed? If so, sorry for wasting time.
Otherwise, would appreicate pointers & comments, especially if anyone has created a ‘definitive’ list,
which would imply some criteria for admission.
================
--
Steve Jenkin, IT Systems and Design
0412 786 915 (+61 412 786 915)
PO Box 38, Kippax ACT 2615, AUSTRALIA
mailto:sjenkin@canb.auug.org.au http://members.tip.net.au/~sjenkin




{kind=link}