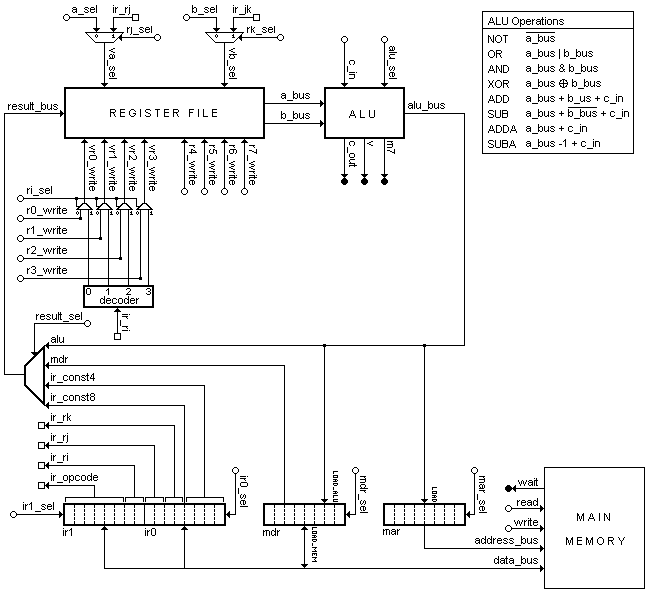
| ir_opcode | ir_ri | ir_rj | ir_rk | ir_const4 |
| bits 15 to 10 | bits 8,9 | bits 6,7 | bits 4,5 | bits 3 to 0 |
| ir_opcode | ir_ri | ir_const8 | ||
| bits 15 to 10 | bits 8,9 | bits 7 to 0 | ||
fetch0: a_sel=7, b_sel=7, alu_sel=AND, r6_write, mar_sel=LOAD;
fetch1: r7_write, a_sel=6, alu_sel=ADDA, c_in, read, ir0_sel=LOAD, if wait then goto fetch1 endif;
fetch2: a_sel=7, b_sel=7, alu_sel=AND, r6_write, mar_sel=LOAD; fetch3: r7_write, a_sel=6, alu_sel=ADDA, c_in, read, ir1_sel=LOAD, if wait then goto fetch3 endif;
goto opcode[IR_OPCODE];
opcode[1]: ri_sel, rj_sel, rk_sel, alu_sel=ADD, goto fetch0;
opcode[3]: a_sel=3, b_sel=3, alu_sel=SUBA, r6_write, result_sel=IR_CONST8, if c_out then goto fetch0 else goto branch endif; branch: r7_write, a_sel=7, b_sel=6, alu_sel=ADD, goto fetch0;
0000 0000 + 1111 1111 (i.e. twos-complement -1) ----------- 1111 1111and note that there was no carry. However, for any other bit pattern on the top, there would be a 1 bit which would cause a carry, which would ripple out on the left-hand side.
LOADI R0, 0 # R0 <- 0 LOADI R1, 1 # R1 <- 1 LOADI R2, 32 # R2 <- 32 loop: NOP # Do nothing LOAD R3, (R2) # R3 <- memory[R2] BEQ R3, end # Stop looping if R3 == 0 ADD R0, R0, R3 # Add number to the running sum in R0 ADD R2, R2, R1 # Move R2 up to the next number JUMP loop # Loop backwards for the next number end: LOADI R1, 30 # R1 <- 30 STORE R0 (R1) # memory[R1] = R0, i.e write result in location 30 HALT # Halt the CPU