System Architecture
(INFT12-212 and 72-212)
Lab Notes for Week 9: Linux Memory Management System
Calls
1 Introduction
2 Using ps to See Memory Allocation
In the first lab you saw that ps could give you details of
all of the processes running on the Unix machine. After connecting
to a different Linux box with SSH, run the following ps command:
$ ps -o user,vsz,rss,pmem,fname -e | less
What does the -e option to ps mean? The columns
that you see for each process are:
- user:
- The user who started the process running.
- vsz:
- The total size of the process in (virtual) memory in kilobytes
as a decimal integer.
- rss:
- The resident set size of the process, in kilobytes as a
decimal integer.
- pmem:
- The ratio of the process's resident set size to the physical
memory on the machine, expressed as a percentage.
- fname:
- The first few character's of the process' name.
Explain the concept of the resident set. Explain why the
resident set size is smaller than the total process size. Where is
the rest of each process' memory?
One reason why the resident set is smaller than the process size is
that Unix processes use shared libraries, similar to DLLs
on Windows systems. The operating system doesn't include the size
of any shared libraries in the resident set, because the libraries
are loaded into memory only once.
3 Using df to See Swap Usage
With a paging virtual memory system using LRU, those least recently
used pages are copied out to disk until they are required again (if
ever). To see the amount of swap space in use, use the command:
$ cat /proc/swaps
Remember that if the swap space is too small, then there is not enough
room to keep the unused pages, and thrashing is likely to
occur. On the other hand, if the swap space is too large, you waste
disk space as the swap space cannot be used to store files.
4 Monitoring Paging Activity
The vmstat program is the best utility to monitor paging
activity. As with the other xxxstat programs,
$ vmstat 2 40
will give 40 vmstat reports, one every 2 seconds, and the first report
is an average since the system was started. Read the manual on vmstat
to see what information it provides. The main memory stats columns
are:
- swpd:
- the amount of virtual memory used.
- free:
- the amount of idle memory.
- buff:
- the amount of memory used as buffers.
- cache:
- the amount of memory used as cache.
- inact:
- the amount of inactive memory. (-a option)
- active:
- the amount of active memory. (-a option)
- si:
- Amount of memory swapped in from disk (/s).
- so:
- Amount of memory swapped to disk (/s).
- bi:
- Blocks received from a block device (blocks/s).
- bo:
- Blocks sent to a block device (blocks/s).
- in:
- The number of interrupts per second, including the clock.
- cs:
- The number of context switches per second.
Watch the memory subsystem activity on the Linux box for a bit. Is
it a problem if the available free memory goes down to nearly zero?
Explain.
The swapped out column is often zero. Therefore, there must be many
pages in memory which are unused but are not paged out to disk. Why
are these unused pages not paged out?
Explain why there are page ins when there is ample free memory?
On my Linux box, while vmstat is running, I'll launch this program
which simply tries to consume as much memory as possible and then
touch all of the pages to makes its working set as big as possible.
Watch the results displayed by vmstat! Compare the amount
of free physical memory before the thrashing process runs and afterwards.
Explain why there is such a difference.
Another program to play with is eatmem.c
which consumes memory without doing anything with it, so its working
set stays small.
5 Components of a Process
A Unix process has several memory components:
- A text section which holds the process' machine code.
- A data section which holds the process' global variables.
Initially, some of the global variables have values, and some do not.
The latter are kept in a section known as the bss section.
- A heap section which is where newly created global variables
are kept.
- A stack section which is where newly created local variables
are kept, as well as function parameters and function return information.
Which of these sections need to be stored as the program image
on disk? Which don't? Why not?
The size program shows the sizes of the text, data and bss
sections in a program's disk image. For example:
$ which ls # Where on disk is ls kept?
/bin/ls
$ size /bin/ls
text data bss dec hex filename
72778 856 944 74578 12352 /bin/ls
Find the size of the bash program on disk. Now use ps
to see how much memory bash actually requires. Why does a
bash process use much more memory then is in the disk image?
Try this out for other Unix programs.
6 Sharing Memory
Because Unix runs on page architectures, it can use page protections
to share sections of memory read-only between processes.
For example, the text section for all kshs is shared read-only.
Another use of page sharing is for shared libraries. These
are subroutines which are common to many programs. The printf()
function is used by nearly all C programs, and so it makes sense to
load it once into memory, and share its page amongst all C processes.
The ldd command can show you what shared libraries are used
by each program:
$ which ls # Where on disk is ls kept?
/bin/ls
$ ldd /bin/ls # Show the shared libraries used
librt.so.1 => /lib/librt.so.1 (0x40023000)
libacl.so.1 => /lib/libacl.so.1 (0x40036000)
libc.so.6 => /lib/libc.so.6 (0x4003d000)
libpthread.so.0 => /lib/libpthread.so.0 (0x40171000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
libattr.so.1 => /lib/libattr.so.1 (0x401c2000)
$ size /lib/libc.so.6
text data bss dec hex filename
1228251 11300 10820 1250371 131443 /lib/libc.so.6
Unfortunately, I can't find a tool which shows where and how each
shared library is loaded into Linux's memory. As with processes, unused
pages in shared libraries are paged out to disk.
Discussion: What disadvantages does a system suffer from if it doesn't
provide some form of shared libraries? What disadvantages does a system
suffer from if it does provide some form of shared libraries?
7 Memory-related System Calls
7.1 Classic Unix Memory System Calls
Until recently, Unix has provided a flat logical address space to
each processes. Available memory locations start at zero and go up
to some address N. The text area (containing machine code) was
fixed in size, and the stack area grew automagically as a process
grew its stack.
The only memory-related system call was to grow or shrink the data
area, also known as the heap, which is used to store global
variables. This system call was sbrk().
#include <unistd.h>
char *sbrk(int incr)
Sbrk() takes a number which indicates by how many bytes to
grow the data area. Negative values allow a process to shrink the
data area. The system call returns the current top address of the
data area; a process can get this information by doing sbrk(0).
On a paged architecture, Unix allocates memory in page units, and
so sbrk() will often allocate more new memory than was requested
by the process.
The sbrk() call is rarely used directly. Instead, most processes
use library routines to create or release new global variables on
the heap. Examples are the C routines malloc(),
calloc()
and free().
Here is an example C program which
uses malloc() and free(). Compile and run it using
the commands you learned in the last lab.
7.2 Recent Unix Memory System Calls
Unix still only provides a flat address space to processes. We now
have system calls to create memory regions between the heap
and stack, and to map file contents to these regions. Currently
there are two different groups of memory syscalls: the SHM group from
System V Unix, and the MMAP group from Berkeley Unix.
7.3 SHM System Calls
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, int size, int flag)
Shmget()
allows a process to create a new shared memory object, or to get access
to a shared memory object created by another process. The key
and flags determine which of the two operations occur. The
size field is used to determine the size of a new object.
The call returns an integer which identifies the object.
Once a shared memory object has been created or accessed, the process
must decide where in its available address space to position the object.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
void *shmat(int shmid, void *addr, int flag)
Shmat()
takes an object identifier, and places the memory region in the process'
address space starting at location addr. The flag
specifies if the object is read-only or read-write.
Another system call, shmdt(),
detaches a memory object from a process' address space. A further
system call, shmctl(),
does other operations like lock the object into main memory, i.e prevent
it from ever being paged out out to disk.
8 MMAP System Calls
Berkeley Unix provides another group of memory system calls with similar
functionality to SHM. Most current Unixes provide one set as system
calls, and have library routines for the other set, which are then
translated.
#include <sys/types.h>
#include <sys/mman.h>
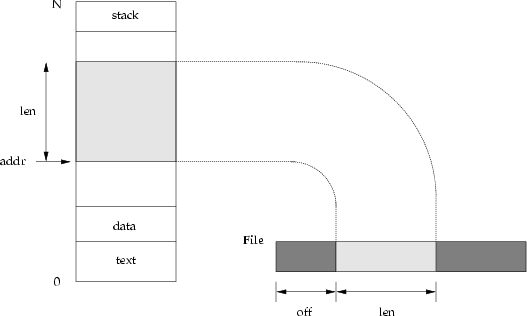
void *mmap(void * addr, size_t len, int prot, int flags,
int fd, off_t offset)
The mmap()
system call does a lot in one call! It creates a memory region starting
at address addr with length len. Prot specifies
if the region is executable, readable and/or writable. Depending on
the flags, the region is private, shareable with other processes,
and can be mapped to all or a portion of a file specified
by fd.
 When a process is finished with the memory region, it can unmap the
region with munmap().
Other system calls like madvise()
tell the system how the process will access the region (sequential,
random), and if the pages should be locked into main memory.
These system calls also allow shared libraries to exist:
if a process requires a shared library, then this is mapped into its
address space as a read-only region at run-time.
Here is an example C program which
uses mmap() to map a file into memory, read some of its contents
and then make changes to the file. Compile and run it using the commands
you learned in the last lab.
When a process is finished with the memory region, it can unmap the
region with munmap().
Other system calls like madvise()
tell the system how the process will access the region (sequential,
random), and if the pages should be locked into main memory.
These system calls also allow shared libraries to exist:
if a process requires a shared library, then this is mapped into its
address space as a read-only region at run-time.
Here is an example C program which
uses mmap() to map a file into memory, read some of its contents
and then make changes to the file. Compile and run it using the commands
you learned in the last lab.
9 Outlook for the Next Lab
In the next lab, we will look at virtual memory management.
File translated from
TEX
by
TTH,
version 3.85.
On 13 Jan 2012, 11:50.