
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 |
Let's try it out: we know that 01011001 is 8910. Flipping the bits gives 10100110. Adding 1 gives 10100111: fortunately there was no carry. So 10100111 is -8910.Flip all the bits and add 1
Let's try it out with 01011001. There are no least significant zeros, and we therefore leave the right-most one unchanged. We flip all the other bits. This gives us 10100111, where the bold indicates the untouched bits. Here's another 8-bit number: 00101100. Question: what is it in decimal? To negate it, we leave the right-most bits and the right-most one untouched, and flip all the other bits, giving 11010100.Scan the number from right to left, leaving all least significant zeros and the first one unchanged. Then flip the remaining digits to the left.
| Signed byte: -8910 | |||||||
| -ve | |||||||
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| Unsigned byte: 128+64+16+4= 21210 | |||||||
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| Signed | Unsigned | |
| Byte | -128 to +127 | 0 to 255 |
| Halfword | -32768 to +32767 | 0 to 65535 |
| Word | -2147483648 to +2147483647 | 0 to 4294967296 |
| Doubleword | -verybig to +verybig | 0 to verybig |
| Location 0 | Location 1 | Location 2 | Location 3 |
| 11001100 | 00000000 | 01010101 | 00001111 |
.data num1: .byte 5 # Store 5 as a byte num2: .half 6 # Store 6 as a halfword, i.e. 16 bits num3: .byte 7 # Store 7 as a byte num4: .word 8 # Store 7 as a wordLet's assume that the assembler stores these numbers consecutively, starting at address 0. Here's how the memory would be allocated:
| Location | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| Value | num1 | unused | num2 | num2 | num3 | unused | unused | unused | num4 | num4 | num4 | num4 |
| Instruction | Result | Comment |
| li Rd, Imm | Rd = Imm | Load register with constant value |
| add Rd, Rs, Rt | Rd= Rs + Rt | Signed addition of 2 registers |
| addi Rd, Rs, Imm | Rd= Rs + Imm | Signed addition of Rs with 16-bit constant |
| addu Rd, Rs, Rt | Rd= Rs + Rt | Unsigned addition of 2 registers |
| addiu Rd, Rs, Imm | Rd= Rs + Imm | Unsigned addition of Rs with 16-bit constant |
| sub Rd, Rs, Rt | Rd= Rs - Rt | Signed subtraction of 2 registers |
| subu Rd, Rs, Rt | Rd= Rs - Rt | Unsigned subtraction of 2 registers |
| sll Rd, Rs, shamt | Rd = Rs << shamt | Shift Rs left by shamt bits, store in Rd |
| srl Rd, Rs, shamt | Rd = Rs >> shamt | Shift Rs right by shamt bits, store in Rd |
| sra Rd, Rs, shamt | Rd = Rs >> shamt | Shift signed Rs right by shamt bits, store in Rd |
 icon, and watch as the two constants are loaded into $t0 and $t1,
then as the addition is stored into $a0.
icon, and watch as the two constants are loaded into $t0 and $t1,
then as the addition is stored into $a0.
Error in wk2add.asm line 7: Runtime exception at 0x00400010: arithmetic overflow Go: execution terminated with errors.With signed instructions like add, if the result exceeds either the maximum or minimum of the signed range, the CPU throws an exception and the program crashes.
value * 10 == (value * 8) + (value * 2), i.e. value * 10 == (value <<3) + (value <<1)Download and load the wk2shiftmult.asm program. Run it and see what it does!
| Instruction | Result | Comment |
| mul Rd, Rs, Rt | Rd = Rs * Rt | No overflows detected |
| mulo Rd, Rs, Rt | Rd = Rs * Rt | Overflows can occur |
| mulou Rd, Rs, Rt | Rd = Rs * Rt | Unsigned, overflows |
| mult Rs, Rt | (hi, lo) = Rs * Rt | 64-bit multipy result |
| multu Rs, Rt | (hi, lo) = Rs * Rt | Unsigned 64-bit multiply result |
| div Rd, Rs, Rt | Rd= Rs / Rt | Signed division |
| divu Rd, Rs, Rt | Rd= Rs / Rt | Unsigned division |
| div Rs, Rt | lo= Rs/Rt, hi= Rs%Rt | Division and remainder |
| divu Rs, Rt | lo= Rs/Rt, hi= Rs%Rt | Unsigned division and remainder |
| rem Rd, Rs, Rt | Rd= Rs % Rt | Signed remainder |
| remu Rd, Rs, Rt | Rd= Rs % Rt | Unsigned remainder |
| Instruction | Result | Comment |
| lb Rd, label | Rd = byte value at label | Sign extended |
| lbu Rd, label | Rd = byte value at label | Unsigned |
| lh Rd, label | Rd = halfword value at label | Sign extended |
| lhu Rd, label | Rd = halfword value at label | Unsigned |
| lw Rd, label | Rd = word value at label | |
| ld Rd, label | (Rd, Rd+1) = doubleword at label | |
| sb Rd, label | byte value at label = Rd | |
| sh Rd, label | halfword value at label = Rd | |
| sw Rd, label | word value at label = Rd | |
| sd Rd, label | doubleword at label = (Rd, Rd+1) | |
| move Rd, Rs | Rd = Rs |
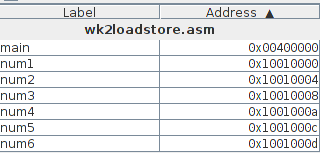
num1: .word 7 # Store 7 as a word into num1 location num2: .word 6 # num2 = 6 num3: .half -10 # Store -10 into 16-bit location num3 num4: .half 3 # num4 = 3 num5: .byte 64 # num5 is only 1 byte long num6: .byte 1Note that I have put things in decreasing size order: this ensures that we don't waste memory due to alignment issues. Each value is only small and would fit into a single byte: for multibyte data sizes, the remaining bytes should be filled with zeros (or ones for the -10 value). Assuming that the assembler stores these adjacent values in memory starting at location 0, predict which bytes will be all zeroes, all ones, or have the bit pattern of the values shown. Remember that multibyte data is stored in little-endian format! Fill in the following table (on paper) with your guesses.
| Location | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |

| Location | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 07 | 00 | 00 | 00 | 06 | 00 | 00 | 00 | F6 | FF | 03 | 00 | 40 | 01 | 00 | 00 | |
| Value | num1 | num2 | num3 | num4 | num5 | num6 | ||||||||||

