The Internet is the catch-all word used to describe the massive world-wide network of computers. The word ``internet'' literally means ``network of networks''. In itself, the Internet is comprised of thousands of smaller regional networks scattered throughout the globe. On any given day it connects roughly 20 million users in over 50 countries.
The World-Wide Web is mostly used on the Internet, but they do not mean the same thing. The Web refers to a body of information, while the Internet refers to the cables and computers of the global network that allow the information on the Web to be transferred.
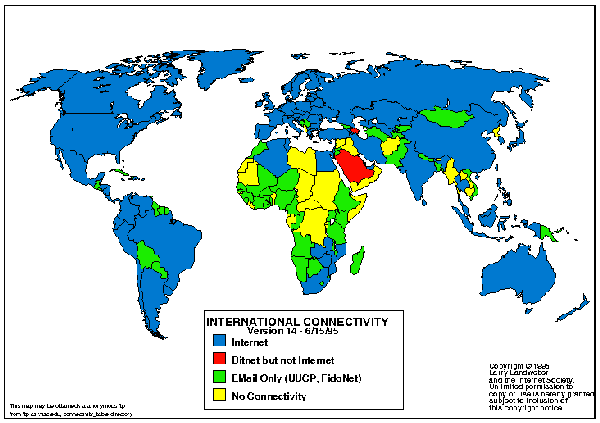
Figure 1. The Countries Connected to the Internet.
In Figure 1, the countries shown in black have Internet connectivity. The number of people with Internet access in these countries varies widely, however. Countries in white may have access to email, local isolated networks, or no connectivity at all.
Nobody ``owns'' the Internet -- although there are companies that help manage different parts of the networks that tie everything together, there is no single governing body that controls what happens on the Internet. The networks within different countries are funded and managed locally according to local policies.
Having access to the Internet usually means that one has access to a number of basic services: electronic mail, interactive conferences, access to information resources, network news, and the ability to transfer files.
The World-Wide Web uses the Internet to transmit documents between computer users internationally. Much in the same way, nobody ``owns'' the World-Wide Web. People are responsible for the documents they author and make available publicly on the Web. Via the Internet, hundreds of thousands of people around the world are making information available from their homes, schools, and workplaces.
This lack of control over the contents of the Web is both an advantage and a drawback. What this means to you is that the information on the Web is continually changing, and something that you found on the Web one day may not be there the next.
It's possible to use World-Wide Web software without having to use the Internet. But Internet access is necessary in order to make full use of and participate in the World-Wide Web.
There are several ways to access the information and the services on the Internet:
To use these methods of Internet information retrieval, you need an application program which can perform each required method. Here are some of the commonly-available Internet application programs:
The methods of Internet access such as FTP, Telnet and SMTP are international standards. This allows users with different computers to transfer information over the Internet. For example, a Unix user could send email with elm to a Mac user, who can read it with Eudora. This is only possible when the access methods are both standardised and non-proprietary. In fact, Internet applications are available on dozens of other platforms than the ones named above, such as OS/2, Amigas, Ataris and VMS.
The World-Wide Web is a collection of hypermedia documents (see below) which can be retrieved over the Internet using a new method of access known as HTTP. Rather than fetching a document with FTP, then having to run an application program to view the document, both of these operations are combined into one.
The World-Wide Web is officially described as a ``wide-area hypermedia information retrieval initiative aiming to give universal access to a large universe of documents''. That's glossy salespeak. What the World-Wide Web has done is provide users on computer networks with a consistent means to access a variety of documents in a simplified fashion.
To access the Web, you run an application program known as a browser. The browser reads documents, and can fetch documents from other sources. Information providers set up hypermedia servers which browsers can get documents from.
The browsers can, in addition, access files by FTP, Telnet, Usenet News and an ever-increasing range of other methods. On top of these, if the server has search capabilities, the browsers will permit searches of documents and databases.
The operation of the Web relies mainly on hypertext as its means of interacting with users. Hypertext is basically the same as regular text on a computer -- it can be stored, read, searched, or edited -- with an important exception: hypertext contains connections within the text to other documents.
For instance, suppose you were able to somehow select (with a mouse or with your finger) the word ``hypertext'' in the sentence before this one. In a hypertext system, you would then have one or more documents related to hypertext appear before you -- a history of hypertext, for example, or the Webster's definition of hypertext. These new texts would themselves have links and connections to other documents -- continually selecting text would take you on a free-associative tour of information. In this way, hypertext links, called hyperlinks or hotlinks, can create a complex virtual web of connections.
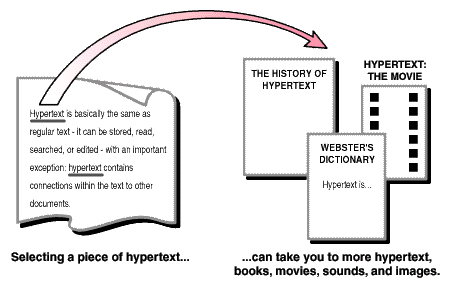
Figure 1. How Hypertext Works.
Hypermedia is hypertext with a difference -- hypermedia documents contain links not only to other pieces of text, but also to other forms of media -- sounds, images, and movies. Images themselves can be selected to link to sounds or documents. Hypermedia simply combines hypertext and multimedia. Here are some simple examples of hypermedia:
The Web, although still in its infancy, has already enabled many of these examples. It facilitates the easy exchange of hypermedia through networked environments from anything as small as two Macintoshes connected together to something as large as the global Internet.
One great advantage of the Web is its extensibility. The designers of the Web realised that new sorts of documents appear as technology grows. They have designed the Web so that, if a browser cannot display a certain document itself (for example, a Word 6 or Powerpoint document), then the browser can pass the document to an external viewer to display the document. So when ``smellovision'' or ``holovision'' documents and viewers become available, the Web will automatically support them.
.au (Sun audio) format.
If your browser is properly configured for sound,
select this link or select the sound icon to hear it. (19k)
![[icon]](graphics/internet.gif) This is a GIF image.
Select this link or the image icon to view it. (122k)
This is a GIF image.
Select this link or the image icon to view it. (122k)
Just as you need an FTP application to use FTP, you need a Web browser in order to access documents on the Web. There are dozens of Web browsers available, some for free and some which are commercially available. Here are the main ones you are likely to encounter:
Note that Netscape is NOT the Web. It is only a browser that allows you to access to Web, and there are many, many other browsers.
Several departments in ADFA provide information on the Web. This information is available either from the main campus Web server ccadfa, or from departmental Web servers.
The Computer Centre machine ccadfa has the ``home page'' for ADFA, some general information about ADFA and the World-Wide Web, and also hosts some of the departmental information, described below. ccadfa is an excellent starting place to find information about where to look on the Web. It has hotlinks to several Web search tools, such as the Harvest Home Page Broker, several places to start looking around the Web, and a Subject-Oriented Index of Web information.
The Library also provides information via the Web, such as the Library newsletter, their opening hours, and information on the Library's catalogue.
Several departments within ADFA provide information on the Web:
The sort of information you are likely to find is:
Every time you start your Web browser, you start at the same Web document; this is known as your home page. The home page acts as your ``home base'': if you point and click on too many hotlinks and get lost, you can get home by clicking on your browser's home icon. The home page should have enough hotlinks to allow you to ``surf the Web'' easily.
It is in your own interest to set up your Web browser to start with a home page which is both close to you and which provides you with pointers to local services. Most browsers come with a default home page which is in the United States; every time you start your browser you have to retrieve this page from the U.S, which may take a long time. So, if your browser doesn't start with the ADFA home page, you should alter your browser's configuration to start with this page. The laboratory session will show you how to do this.
There are two other meanings for the term ``home page''. The top-level document on each Web server is known as its home page, and should have hotlinks that allow you to start from there and find every Web document on that server. Some examples of server home pages are:
The final meaning for ``home page'' is the Web document you write that describes yourself, and has hotlinks to other documents that you are interested in. Here are some example home pages at ADFA:
Each document on the Web has a unique name, its Uniform Resource Locator. Examples are:
Each URL has several fields, shown in bold below.
access_method :// machine_name [ : port] / directory_name / file_name
The first field of a URL describes the Internet method used to access the document:
The second field of a URL usually gives the name of the Internet server where the document resides. From the examples above, wuarchive.wustl.edu, info.cern.ch and dra.com are Internet servers. Each name is broken up into several components, and each component gives you a clue as where the server is and what it is used for. As an example, octarine.cc.adfa.edu.au means ``the machine octarine in the Computer Centre at ADFA, which is an educational institution in Australia''.
In particular, the last component of a server's name tells you which country it is in. Appendix A lists the possible values and the country each represents. The main suffixes your are likely to encounter are:
The third field of a URL, which is optional, describes the port or connection point on the Internet server that the browser must connect to.
The fourth and fifth fields of a URL describe the exact location of the document on the Internet server. If the document is located within a set of directories (also known as folders, then the name of each directory is given, separated by slashes. The last field is the document's name, and it usually ends in .html or .htm .
Now it's time for you to try out the things we've just covered. Your goals for the first laboratory session of this workshop are:
One of the hardest things to do with the Web is to actually find something that you are interested in. It's easy to ``surf the 'net'' (follow hotlinks), but actually searching for certain information is much more difficult.
The difficulty of searching the Web is that the Web is an anarchy of documents distributed around the world, and maintained by thousands of individuals. There is no central repository of documents; there isn't even a central bibliographic index of documents.
The problem of searching the Web is exacerbated by the fact that the documents on the Web are not static. Every day, individuals change the contents of their Web documents, they remove documents from the Web, they add new documents to the Web, and they change the URLs of existing documents.
Despite these problems, people are beginning to build indexes of information on the Web. Because of the architecture of the Web, these indexes can never be complete, correct and authorative; however, they are better than nothing. So let's look at how current Web indexes are compiled, and how to search these indexes for information.
The simplest form of Web searching is to follow hotlinks until you come across a document which is relevant to what you are searching for. Often, a relevant document will have hotlinks to other documents closer to what you were searching for.
Another information resource which many people overlook is to ask friends and colleagues if they have seen any relevant Web documents. This works especially well if there is a set of people who are all interested in a particular topic, or related topics.
Many organisations in the world are setting up Web catalogues, to help Web users search for information quickly and easily. At the moment, there are two main ways of cataloging the information on the Web.
With the first method, the author of a Web document send information about that document to the maintainers of the index, who then add the information into the index. The information usually cataloged contains:
This method only works if the authors bother to register their documents. One advantage of this is that the documents registered usually stay longer on the Web and are `maintained' better than non-registered documents.
The other method of cataloging the Web is to write a program known as a Web crawler, Web robot or Web spider. This program starts at the home page of a server, and follows all the hotlinks on that page. For each hotlink, the program retrieves the document, saves the details of the document (location, author, keywords etc.) in a database, and follows the hotlinks that are contained in that document.
It should be apparent that, if Web documents have two or more hotlinks on average, then the Web crawler will have an exponentially increasing number of hotlinks to follow. Eventually, a Web crawler will have retrieved all the documents on the Web.
This exponential growth of documents, combined with the rate of change of documents on the Web, means that by the time a Web crawler has cataloged a small percentage of the Web, most of its catalogue will be out of date. Therefore this method is now being used less and less.
Some of the catalogues are made available in a form that is ``tree'' structured, with a top-level page pointing at category pages, and those pages pointing at sub-category pages etc. By following enough hotlinks, you should be able to narrow your search to what you were looking for.
Examples of catalogues that use trees of hotlinks are:
Following hotlinks can be a real pain, as you are never sure if you will eventually find the information you are after. Another method of finding information is to use a Web catalogue that has an on-line search facility. These are often known as search engines.
To use a search facility, you retrieve a Web page from the server which has a fill-in form. You fill in the form as indicated, click on the `Submit' button, and your query is transmitted to the remote Web server. It searches its catalogue according to your query, and returns a second Web page with the results of your query.
The sorts of devices you are likely to find on a Web form are:
As an example, Figure 3 shows the fill-in form for the Harvest Home Page Broker at
http://www.town.hall.org/Harvest/brokers/www-home-pages/query.html
has a text box for you to enter your query string, a number of toggle buttons
to choose what information is returned to you, and a menu bar to select the
maximum number of results that can be returned to you.
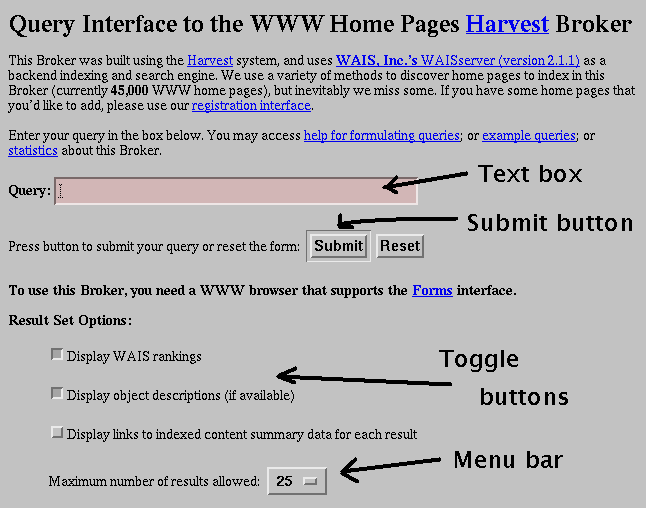
Figure 3. The Harvest Home Page Broker Form.
If your search was sucessful, the Web page returned to you should contain a number of hotlinks to Web documents related to your query. Depending on the search engine, the result may also contain some information about each document, and a measure of the `match' between the document and your query.
The number of searchable Web catalogues is growing daily, so the following list contains a number of well-known searchable catalogues, and also some Web pages that maintain hotlinks to existing and new searchable catalogues.
By now, you should be able to find and retrieve Web documents and search for information about a particular topic. This section will show you how you can use your Web browser to make your use of the Web more efficient and effective.
Firstly, the documentation for Netscape, Mosaic and Lynx is on the Web. This means it takes time to retrieve it from the remote server, and you can't flick through it like a paper copy. These browsers have a help button which you can click on to automatically retrieve the documentation.
Each browser has a set of buttons which perform actions. You should have seen some of these buttons in the lab sessions, such as the `Home' button which returns you to your home page, and the `Back' button which takes you back one page. Some other buttons which are quite useful are:
One of the main problems with using the Web is to remember where you've been recently, and to remember all the useful Web pages you found. The first can be performed with Netscape's `Go' button, and Mosaic's `Navigate/View History' menu item. These list the Web pages you have recently retrieved, in order of retrieval. You can click on any of the entries in the list to return to that page.
Both Netscape and Mosaic allow you to keep a list of Web pages that you are interested in. This is known as a bookmark list or a hotlist. The list is accessible from the Netscape `Bookmark' menu item, or the Mosaic `Navigate' menu item. From here, you can see your bookmarks, add the current web page into your bookmark list, and view/edit your bookmarks.
To add a new page into your bookmark list under Netscape, simply pull down the `Bookmark' menu item and click on the `Add Bookmark' line. The page is now in your hotlist.
Discussion is needed on hierachical bookmark lists under Netscape.
This entire section needs writing.
One of the major drawbacks of the Web is that to view a document, you must first retrieve it from a remote server. If that server is a long way away, is very busy or is down, then you may not be able to retrieve the document in a reasonable time. Even worse, if you have retrieved a document and then show it to a friend (or give them the URL), they also have to retrieve the document from the server with their browser.
This can be avoided by keeping what is known as a cache of Web information. The cache holds those pages that have been recently retrieved. When your browser needs a document, it firsts checks to see if the document is in the cache; if it is, then the browser gets the document from there.
If the cache is big enough, and the network between your browser and the cache is fast, then using the cache will give you and your colleagues a great improvement in the speed of downloading Web pages. The disadvantage of a cache is that the cache may hold a out-dated copy of a document that has been altered on the original Web server. This can be avoided in one of two ways:
You can configure your browser to use a cache by setting it to send all document requests through a proxy, a machine which acts on the browser's behalf. If that proxy keeps a cache, then all browsers using the proxy will get the benefit of the proxy's cache.
At ADFA, the Web server in the Computer Centre, www.adfa.edu.au, is a proxy server which keeps a 500 Megabyte cache of Web pages. We recommend and urge you to use this proxy server to improve your Web retrievals. To use this proxy server, click on the following Netscape menu items in order:
You will be given a list of Web retrieval methods (ftp, gopher, http and wais). Fill in the text boxes for each of these services with www.adfa.edu.au, and fill in the port numbers for these services with the number `80'. Then click on `OK'. You will now be using the ADFA proxy server as your cache. If you are using a browser other than Netscape, consult your local computer administrators about configuring it to use a caching proxy server.
Stop Press. The ADFA Computer Centre is experimenting with a new caching proxy server which is much faster than the current one, and they plan to replace the existing proxy server with this new one. You can try out the new proxy server by configuring your browser to use harvest.adfa.edu.au as a proxy on port 3128 for ftp, gopher and http. Wais is not supported at the moment.
It's time for you to try out the things we've just covered in the second day of the workshop. Your goals for the second laboratory session are:
We hope you have not only enjoyed this Web workshop, but have gained some useful skills to make effective and efficient use of the Web. We are very interested in feedback so that we can improve this workshop. If you have any comments or suggestions, please pass them on the lab attendants, the presenter, or email them to wkt@cs.adfa.edu.au
The content of this workshop is available on the Web at the URL http://www.cs.adfa.edu.au/Webintro
The sections on the Internet and Hypermedia were written by Kevin Hughes from Enterprise Integration Technologies, and are available on the Web page http://www.eit.com/web/www.guide/
A program that runs on a computer to perform a certain application. Network applications use standard protocols to intercommunicate.
The term Netscape uses for a hotlist.
Another term for a Web browser.
A method of accessing files that are publically available on the Internet. Instead of using an FTP application and logging in as yourself, you log in using anonymous as your account name, and you give your email address as your password.
Electronic mail. Internet email applications such as Eudora use the SMTP and POP protocols to send and receive personal mail. They cannot be used to access non-Internet email.
An application program which is not built into a Web browser, but is used by the browser to display documents that the browser cannot display.
An Internet email application that can run on both Macs and Windows.
An FTP application program that transfers files, which runs on Macs.
A Web page with objects that you can modify, such as text boxes, toggle buttons, radio buttons and menu bars. When you complete the form and press the `Submit' button, the details of the form are sent to a server for processing, and the server returns a new Web page to you. This is commonly used by Web search engines.
File Transfer Protocol, the standard Internet method of transferring files. Applications such as Fetch and Rapid Filer use FTP to transfer files.
The Web page that you always start at when you run your Web browser. The term is also used to describe the top-level Web page of a Web server, or a Web page that describes a particular person.
Another term for a hyperlink.
A list of URLs that your Web browser keeps for you. You can add new URLs to the hotlist, thus allowing you to remember the location of documents you find useful.
HyperText Transfer Protocol. The method that is used to transfer Web documents over the Internet.
An electronic link from one hypertext document to another. You normally follow a hyperlink by clicking your mouse on a highlighted or underlined word.
Hypertext with a difference -- hypermedia documents contain links not only to other pieces of text, but also to other forms of media -- sounds, images, and movies. Images themselves can be selected to link to sounds or documents. Hypermedia simply combines hypertext and multimedia.
Text on a computer (which can be stored, read, searched, or edited), with connections within the text to other documents.
Images that appear within a hypermedia document, as opposed to images that are separate to that document.
A marketing term used by frothing visionaries to try and sell their concept of a global information network. They have trouble understanding that such a thing already exists, and that their vision is an inadequate version of what the Internet provides today.
The massive world-wide network of computers, comprised of thousands of smaller regional networks scattered throughout the globe. On any given day it connects roughly 20 million users in over 50 countries.
A text-based Web browser, from the University of Kansas.
A bar of options in a Web form which, like radio buttons, allows you to select one value from a set of values.
A popular Web browser, from the National Centre for Supercomputing Applications. It runs on Unix, Macs and Windows.
A term used to describe a presentation that uses more than one medium. For example, a computer presentation that provides text, graphics, animation, speech and sound effects is a multimedia presentation.
Another term for the Internet.
Another term for the Internet.
One of the most popular Web browsers, from Netscape Communications Corporation. It runs on Unix, Macs and Windows.
Another term for Usenet News.
A well-defined method by which two computers can properly communicate.
A machine that acts on your behalf to communicate with other servers. On the Internet, proxy servers are mainly used in conjunction with firewalls (beyond the scope of this glossary). A proxy server with a cache helps to improve network efficiency by reducing redundant imformation transfer.
A collection of toggle buttons in a Web form where only one button in the set can be turned on at any time. These are used to select one value from a set of values.
An FTP application program that transfers files, which runs on Windows.
A computer that is connected to the Internet, and which provides information to be retrieved by application programs.
Another term for the Information Superhighway.
A colloquial (and often pejorative) term which means to browse the information on the Web and on the Internet by following hotlinks and other references. In the pejorative sense, the person browsing is idly browsing without any goal and without accomplishing anything useful.
The standard Internet method of logging into remote computers. Also the name of several application programs that use this method.
A field in a Web form where you can enter a string of text.
A button in a Web form which you can turn on or off. This is used, for example, to select a case-sensitive or -insensitive search.
Universal Resource Locator. A textual string that uniquely defines the location of a document on the Web. It gives the full name of the computer where the document is kept, the location of the document on that computer, and the method used to access that document.
The information posted daily on the Internet, and propagated to nearly all the machines on the 'net. There are scores of interest areas within Usenet News.
The Web is the vast collection of hypermedia documents which can be retrieved over the Internet using a Web browser.
Another term for the World-Wide Web.
An application program that retrieves and displays Web documents. It may need external viewers to display some documents.
A Web server whose main role is to catalogue and index some of the documents on the Web, and which allows you to search the index to find information about a particular topic. The two main sorts of catalogues are hotlink-style catalogues, where you follow hotlinks to narrow your search, or Web search engines which provide a fill-in form where you can enter your query directly.
A computer program which starts at a single Web document, and follows the hotlinks from there to slowly retrieve and map the entire contents of the Web. The rate of document change on the Web is making this method of cataloging the Web more and more impractical. The terms Web robot and Web spider are equivalent.
A hypertext of hypermedia document that is available over the Web.
Another name for a Web document. Many documents on the Web are small, and so they more closely resemble a printed page than a full document (newspaper, magazine, book, chapter, etc.).
Another term for Web crawler.
A Web catalogue which provides a fill-in form where you can enter a query on its Web index directly.
Another term for Web crawler.
An acronym for the World-Wide Web.
Another acronym for the World-Wide Web.
ad Andorra ae United Arab Emirates af Afghanistan ag Antigua and Barbuda ai Anguilla al Albania am Armenia an Netherlands Antilles ao Angola aq Antarctica ar Argentina as American Samoa at Austria au Australia aw Aruba az Azerbaijan ba Bosnia and Herzegovina bb Barbados bd Bangladesh be Belgium bf Burkina Faso bg Bulgaria bh Bahrain bi Burundi bj Benin bm Bermuda bn Brunei Darussalam bo Bolivia br Brazil bs Bahamas bt Bhutan bv Bouvet Island bw Botswana by Belarus bz Belize ca Canada cc Cocos (Keeling) Islands cf Central African Republic cg Congo ch Switzerland ci Cote D'Ivoire (Ivory Coast) ck Cook Islands cl Chile cm Cameroon cn China co Colombia cr Costa Rica cs Czechoslovakia (former) cu Cuba cv Cape Verde cx Christmas Island cy Cyprus cz Czech Republic de Germany dj Djibouti dk Denmark dm Dominica do Dominican Republic dz Algeria ec Ecuador ee Estonia eg Egypt eh Western Sahara es Spain et Ethiopia fi Finland fj Fiji fk Falkland Islands (Malvinas) fm Micronesia fo Faroe Islands fr France fx French European Territories ga Gabon gb Great Britain (UK) gd Grenada ge Georgia gf French Guiana gh Ghana gi Gibraltar gl Greenland gm Gambia gn Guinea gp Guadeloupe gq Equatorial Guinea gr Greece gt Guatemala gu Guam gw Guinea-Bissau gy Guyana hk Hong Kong hm Heard and McDonald Islands hn Honduras hr Croatia (Hrvatska) ht Haiti hu Hungary id Indonesia ie Ireland il Israel in India io British Indian Ocean Territory iq Iraq ir Iran is Iceland it Italy jm Jamaica jo Jordan jp Japan ke Kenya kg Kyrgyzstan kh Cambodia ki Kiribati km Comoros kn Saint Kitts and Nevis kp Korea (North) kr Korea (South) kw Kuwait ky Cayman Islands kz Kazakhstan la Laos lb Lebanon lc Saint Lucia li Liechtenstein lk Sri Lanka lr Liberia ls Lesotho lt Lithuania lu Luxembourg lv Latvia ly Libya ma Morocco mc Monaco md Moldova mg Madagascar mh Marshall Islands ml Mali mm Myanmar mn Mongolia mo Macau mp Northern Mariana Islands mq Martinique mr Mauritania ms Montserrat mt Malta mu Mauritius mv Maldives mw Malawi mx Mexico my Malaysia mz Mozambique na Namibia nc New Caledonia ne Niger nf Norfolk Island ng Nigeria ni Nicaragua nl Netherlands no Norway np Nepal nr Nauru nt Neutral Zone nu Niue nz New Zealand (Aotearoa) om Oman pa Panama pe Peru pf French Polynesia pg Papua New Guinea ph Philippines pk Pakistan pl Poland pm St. Pierre and Miquelon pn Pitcairn pr Puerto Rico pt Portugal pw Palau py Paraguay qa Qatar re Reunion ro Romania ru Russian Federation rw Rwanda sa Saudi Arabia sb Solomon Islands sc Seychelles sd Sudan se Sweden sg Singapore sh St. Helena si Slovenia sj Svalbard and Jan Mayen Islands sk Slovak Republic sl Sierra Leone sm San Marino sn Senegal so Somalia sr Suriname st Sao Tome and Principe su USSR (former) sv El Salvador sy Syria sz Swaziland tc Turks and Caicos Islands td Chad tf French Southern Territories tg Togo th Thailand tj Tajikistan tk Tokelau tm Turkmenistan tn Tunisia to Tonga tp East Timor tr Turkey tt Trinidad and Tobago tv Tuvalu tw Taiwan tz Tanzania ua Ukraine ug Uganda uk United Kingdom um US Minor Outlying Islands us United States uy Uruguay uz Uzbekistan va Vatican City State (Holy See) vc Saint Vincent and the Grenadines ve Venezuela vg Virgin Islands (British) vi Virgin Islands (U.S.) vn Viet Nam vu Vanuatu wf Wallis and Futuna Islands ws Samoa ye Yemen yu Yugoslavia za South Africa zm Zambia zr Zaire zw Zimbabwe com US Commercial edu US Educational gov US Government int International mil US Military net Network org Non-Profit Organization arpa Old style Arpanet nato Nato field