Warren Toomey, Computer Science, ADFA
One of the causes of poor Internet performance is its large number of users.
One other cause is the set of sub-optimal techniques for detecting and
utilising available bandwidth in the TCP transport protocol. Although TCP
is now a mature transport protocol, its original design limits its
effectiveness at alleviating network congestion.
Recent work on TCP, known as TCP Vegas, purports to improve the network
congestion control of TCP. This seminar looks at the congestion control and
bandwidth detection techniques of both TCP and TCP Vegas, and shows where
they are deficient. To overcome such network problems, a radical new congestion
control framework for the Internet will be introduced and examined in detail.
Simulation results which compare TCP, TCP Vegas and the new congestion control
framework will be reviewed. These show that the new framework can reduce packet
loss with the Internet by as much as 500, compared to TCP. They will also
reveal the deficiencies in the Vegas modifications to TCP.
Network congestion is a large problem in the Internet. Characteristics are packet loss and large packet delays.
Congestion stems from the offered load on the Internet, plus its inherent design.
Because design is now difficult to modify, main solutions focus on limiting offered transmission load to that which can be delivered.
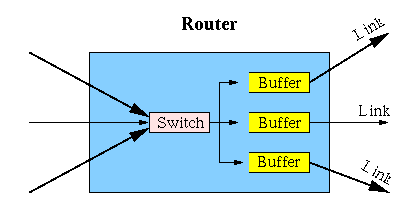
Routers determine how to route incoming packets, buffer them before transmission, and finally retransmit them.
Buffer queue lengths increase if the packet arrival rate exceeds the transmission rate. Processing delays within the router slow down retransmissions.
Congestion occurs when queue lengths are above 1. Packets are delayed: as the queue lengths grows, so does the transmission delay. Packet loss occurs when buffer memory is exceeded, and packets must be discarded.
Congestion results from the combination of: packet load, network topology, link speeds, amount of buffer memory, router processing speed, basic network design.
All sources of network traffic should limit their transmissions to minimise network congestion. This is often done at the transport level.
TCP uses a dynamic sliding window to control admission of packets. The window is increased if no packets are lost, and is decreased when packets are lost.
TCP's window mechanism has changed significantly since RFC 793: Multiplicative Decrease & Additive Increase, Slow Start, Silly Window, Fast Retransmit.
The version of TCP with these changes is known as TCP Reno. TCP's window mechanism, once elegant, is now an ugly set of heuristics.
TCP must predict the round-trip time, in order to detect packet loss. This controls the window size, and hence TCP's flow rate.
Round-trip times have shown to be extremely unpredictable. High variance due to: varying buffer sizes in routers, changes in traffic density along a source/destination path.
If TCP under-estimates the round-tip time, it retransmits a packet unnecessarily.
If TCP over-estimates the round-trip time, it may delay the transmission of a new (or apparently lost) packet, thus wasting available bandwidth.
TCP's round-trip time estimation mechanism has also changed significantly since RFC 793: it is now ugly, and still not good at predicting round trips.
TCP increases its window size until packets are lost, then reduces it. This tends to indicate that a router lost the packet to buffer overflow. TCP will oscillate its window size (and hence flow rate) around the point of buffer overflow.
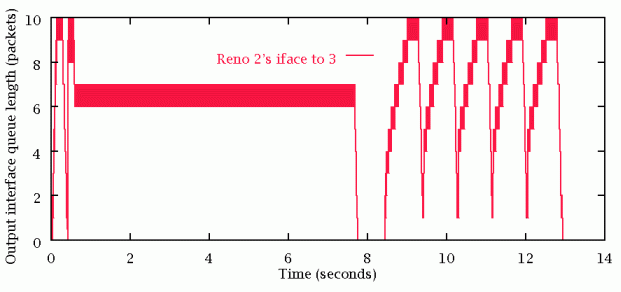
Even if more bandwidth becomes availble, TCP will still throttle up until packets are lost again. Thus, it is likely that many TCP packets will be lost due to router congestion.
Further improvements to TCP, dubbed TCP Vegas, were proposed in 1994. These alter the current dynamic window mechanisms in an attempt to reduce network congestion.
The initial results for Vegas showed that it reduced packet loss dramatically, compared to TCP Reno. However, the results were drawn from very simple network scenarios.
Other researchers have cast doubts on the overall improvement of the TCP Vegas proposals in sophisticated network environments.
As part of my Ph.D work, I examined the performance of TCP Reno and TCP Vegas in non-trivial network environments.
Traditional network congestion techniques treat the network as a `black box': push packets in, see what happens. Routers experience congestion, but have no means to comunicate this to the sources of traffic, e.g to a TCP source.
Newer techniques such as DecBit and Source Quench transmit one bit of
congestion information to sources:
Shut Up!
My congestion control proposal is:
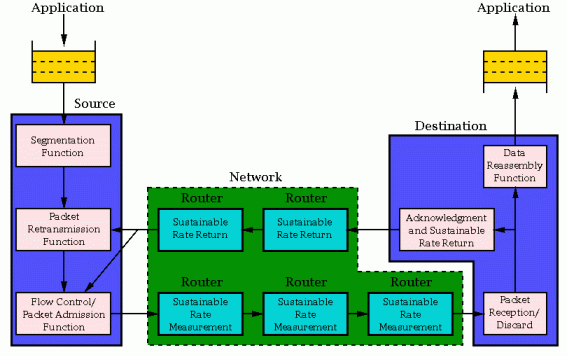
All rate information is measured in bits per second. Assumption: links between routers have a fixed bandwidth in bits per second.
This framework requires that:
In this framework, TCP must be discarded, as it is window-based. Routers must be extended to set sustainable rates. UDP is also unusable.
I have produced a new transport protocol, TRUMP, which replaces TCP and which also offers ``fixed rate'' services, which helps to replace UDP.
However, my focus is on the methods used to set sustainable rates, and to show that the framework does reduce network congestion.
Every packet from source to destination has the fields:
Desired_Rate: Desired bit rate by source: it can be infinity.
Rate: Bit rate allocated to flow by a router: it starts at infinity.
Bottle_Node: The router which set the Rate field.
In packets from the destination to the source:
Return_Rate: The last Rate field to the destination.
Note that a flow of Acknowledgments is itself a flow of traffic:
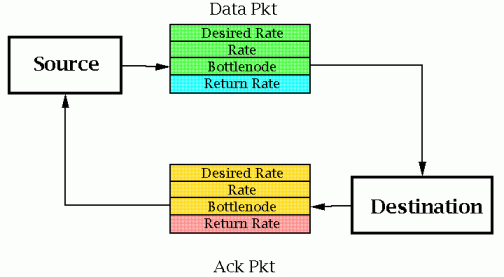
Thus, packets must have both sets of fields, in both directions.
TRUMP is a rate-based, reliable transport protocol. It provides most of the functionality of TCP.
TRUMP's transmission rate is provided by the Network's rate values.
Flow control and error detection/recovery completely separate.
Explicit/implicit connection setup: handshaking delay is optional.
No window: TRUMP works on high-speed large-latency networks.
Applications may ask for an infinite desired rate, or a finite one. Reliability can also be disabled. The latter two are useful for voice/video transmissions.
Sporadic data transmission (2 or 3 packets) not well handled.
The TRUMP protocol has been verified using the Spin verification tools.
Each router must set rates for its traffic flows. This must be done in a distributed fashion. The lowest rate becomes the Sustainable Rate for each flow.
RBCC is the algorithm in each router which performs this task. There are some heuristics associated with the algorithm.
RBCC requirements:
Fairness is difficult, especially where different flows have different desired rates. To ovecome this, I impose the rule:
A flow has a desired rate D and has an existing rate allocation R from its bottleneck router. The flow's limiting rate L is R if we are the bottleneck router, otherwise min(D,R).A flow with limiting rate L should receive the same rate allocation A as all flows with limiting rates L, unless AL. In the latter case, the flow is allocated L, and the difference, A - L, is distributed to the flows with higher limiting rates, according to this rule.
for (c= head_of_flow_list; c!=NULL; c= c->next) {
allocation = bandwidth_left / flows_left;
if (c->lim_rate > allocation) {
c->rate= allocation; /* We are bottleneck */
} else {
allocation= c->rate = c->lim_rate;
}
bandwidth_left -= allocation; flows_left--;
}
Results:
The RBCC algorithm is O(N), N is the set of flows crossing the routers. Heuristics reduce the frequency that RBCC must be used.
RBCC appears to meet all the requirements listed above.
The new framework was compared against TCP Reno and Vegas in a number of hand-crafted network scenarios.
Each was designed to highlight a particular congestion problem, and to observe how each system reacts to it.
The REAL network simulator was used. Significant modifications were done to implement the rate-based congestion control framework.
Results obtained by the simulations:
A simple scenario with one traffic flow, one route and one congestion point.

Reno loses packets (shown by previous queue length graph). Vegas & TRUMP do not. Link utilisation is good for all three.
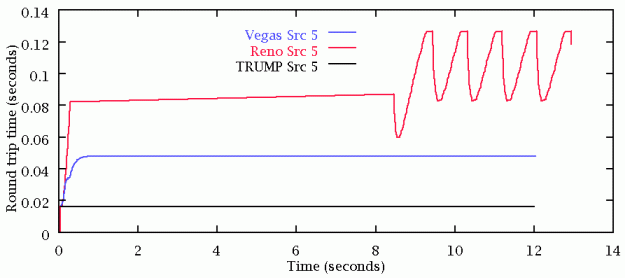
Round-trip times show effect of router queue lengths.
Several traffic flows and 1 congestion point. Flows start at different times. Optimal rates at any time can be calculated.
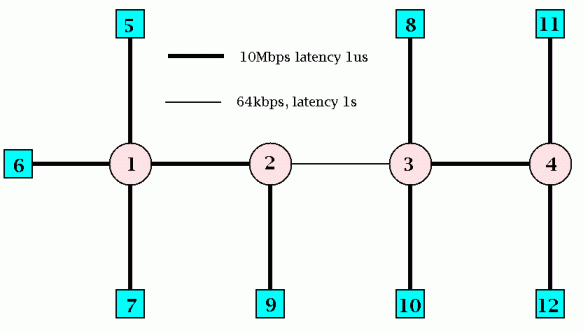
TRUMP/RBCC gives quite different traffic characteristics to Reno & Vegas:
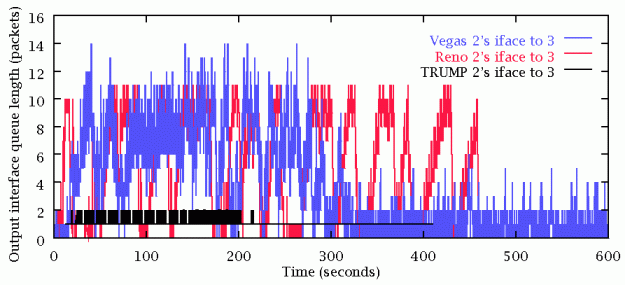
Scenario 5 highlights unfair resource usage due to the spatial distribution of sources.
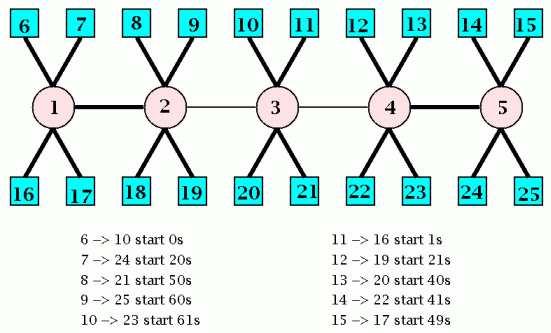
TRUMP/RBCC sets well-behaved rates for all sources. No packets are lost.
Queue sizes are lower for TRUMP than for TCP. TCP Reno loses 405 packets. TCP Vegas loses 140 packets.
TRUMP/RBCC achieves higher link utilisations than TCP (10% higher).
Long-haul flows (sources 7, 9, 10, 12, 13 and 15) end much later for TCP than for TRUMP. Some short-haul TCP flows end earlier. Thus, TCP discriminates against long-haul flows.
In 8 hand-crafted scenarios, Reno lost 1,563 packets, Vegas lost 2,956. TRUMP/RBCC lost none.
Link utilisation was higher for TRUMP/RBCC.
Router queue lengths were around 2 for TRUMP/RBCC, above 2 for TCP.
Round-trips were lower for TRUMP, and had much lower variance, than TCP.
500 randomly-generated scenarios were simulated to gain statistical comparison of TRUMP/RBCC against TCP.
In each scenario: 9 routers, 15 sources, 15 destinations. Each source transmits 1,500 packets. Links were a mixture of `hi-speed' and `low-speed' links.
Low speed links had bit rates 100 times lower than high speed links. Low speed links had latencies 10,000 times larger than high speed links.
In each simulation there is a router which has the highest average buffer queue length. This router is the most congested node in the network. The optimum router length is 1 packet.
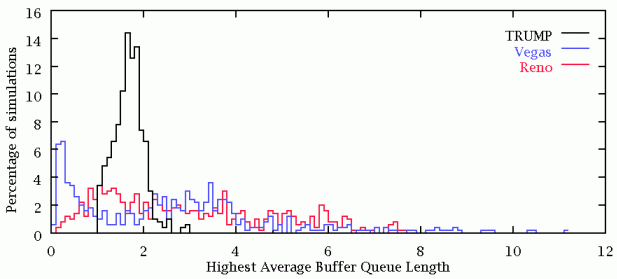
Clearly, TRUMP/RBCC keeps the queue length in the congested router between 1 and 2 packets.
TCP spreads queue lengths between 0 and 8. Either the router has no packets to send (inefficient), or it has too many packets to send (congested).
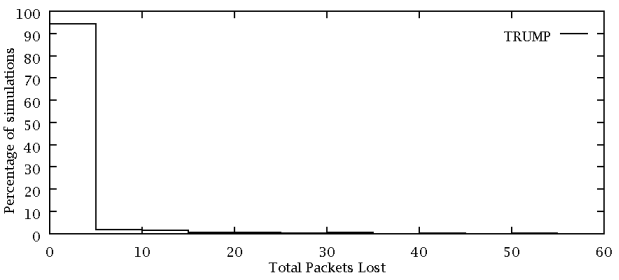
Distribution of total packets lost per simulation by TRUMP/RBCC is shown above. An excellent distribution, skewed towards 0 packets lost per scenario. 458 out of 500 scenarios lost no packets. TRUMP/RBCC lost 551 packets, a loss of roughly 0.002%.
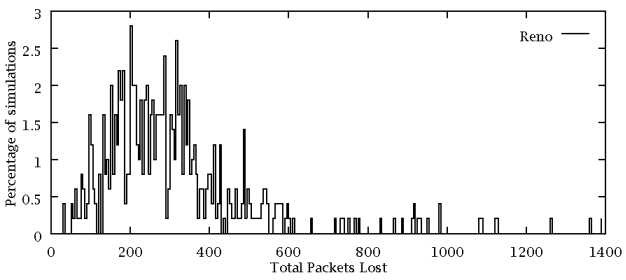
Reno's distribution is shown above. TCP Reno loses 155,833 packets in total (0.7% loss).
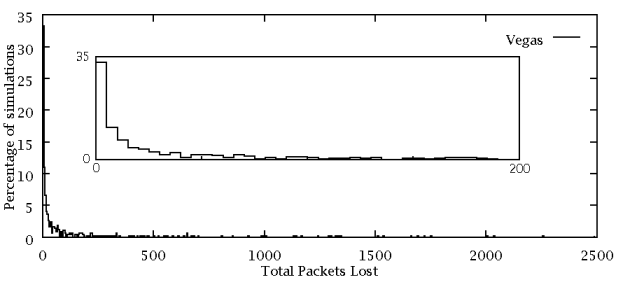
Vegas's distribution is shown above. TCP Vegas loses 70,111 packets in total (0.3% loss).
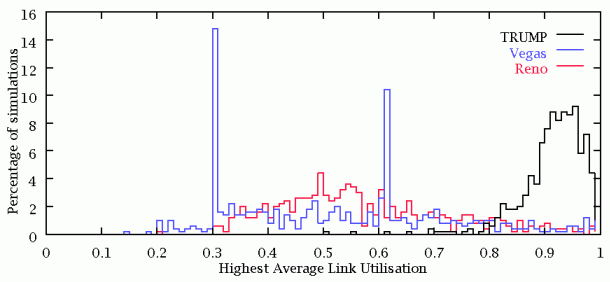
TRUMP/RBCC obtains higher overall link utilisation than either TCP. I have no explanation for the two Vegas spikes.
End-to-end variance of sources is important to time-sensitive network traffic such as voice and video data transmission.
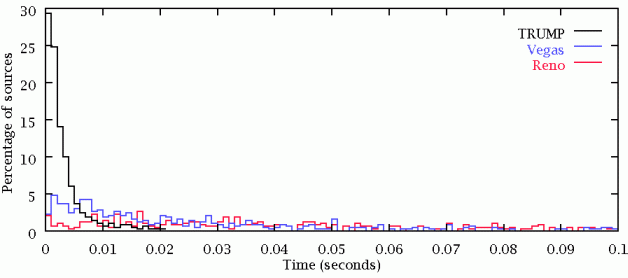
All TRUMP sources achieved an end-to-end standard deviation of less than 22 milliseconds, with 90% of the sources obtained a standard deviation less than 6 milliseconds.
90% of TCP Reno sources obtained a standard deviation less than 280 milliseconds, and 90% of TCP Vegas sources obtained a standard deviation less than 145 milliseconds. Clearly, the arrival times of TRUMP packets are more predictable than for TCP.
The operation of the TRUMP protocol and the RBCC algorithm, as described in my thesis, are influenced by a number of static parameters. Some parameters take a range of non-integral values.
I attempted to improve the congestion control of TRUMP/RBCC by iterating over the tuple space of the parameters.
Each set of parameters took 7 hours to simulate. I only sampled a small number of parameter sets in the tuple space.
The parameters do influence the characteristics of the framework, congestion and otherwise. 2 parameters can have a significant negative impact on the framework's congestion control performance.
One set of parameter values halved packets losses from 551 (0.002%) to 259 (0.0011%). This packet loss is 600 times better than TCP Reno, and 270 times better than TCP Vegas.
The new framework, with TRUMP as the transport protocol, and RBCC in each router, gives significantly better congestion control than TCP. It gives a packet loss result orders of magnitude lower than TCP.
Results for router queue lengths, link utilisation, rate allocation and end-to-end variance confirm the congestion control performance of the framework.
Although RBCC is a good algorithm to choose sustainable rates, other algorithms may be more efficient. In particular, O(1) or O(logN) algorithms should be constructed.
To work, the new congestion control framework must be implemented in every Internet-capable computer and router. IPv6 would permit the router-level operation as an extension. End machines must be persuaded to discard TCP entirely.
The heuristics and parameters employed by both TRUMP and RBCC are somewhat simplistic and static. These can be improved or replaced.